ChatGPT en andere tools voor generatieve AI worden steeds vaker ingezet om teksten te (helpen) schrijven op het web. Je kunt je de vraag stellen hoe correct al die teksten dan zijn, maar er liggen nog grotere problemen op de loer. Want wat als de volgende versie van ChatGPT ook wordt getraind op die teksten? Dat zou desastreus zijn voor de kwaliteit…

Koen Vervloesem
ChatGPT (https://chat.openai.com), ontwikkeld door OpenAI (https://openai.com), is een chatbot gebaseerd op een large language model (LLM). Het is getraind op teksten van mensen en kan zo zelfstandig teksten aanvullen of opstellen. ChatGPT is zo opgezet dat je in een tekstveld kunt ‘chatten’. Je stelt een vraag, en de chatbot formuleert een antwoord. Dat is in gewone taal, afhankelijk van de taal waarin je je vraag hebt gesteld (ChatGPT kent ook Nederlands), en het resultaat kan voor een tekst van een mens doorgaan.
Ondertussen zijn er ook al allerlei tools ontwikkeld om de chatbot te integreren in onze dagelijkse software. En Microsoft wil ChatGPT in zijn kantoorpakket Office 365 integreren. Dat zou je moeten helpen om je writer’s block in Word te overkomen, om sneller presentaties te maken in PowerPoint, om professionele grafieken te maken in Excel en om je e-mails in Outlook in jouw plaats te schrijven. Het aantal automatisch gegenereerde teksten op internet zal dan ook alleen maar toenemen zodra tools voor generatieve AI voor iedereen binnen handbereik komen.
 |
|
Confused-robot (gegenereerd met DALL-E) |
Populair onder WordPress-gebruikers
Maar velen wachten niet tot de integratie van ChatGPT met onze tools om de teksten ervan dagelijks te gebruiken. Nu al worden heel wat teksten die op het web verschijnen automatisch gegenereerd. Het is moeilijk om daar een cijfer op te plakken omdat velen niet zullen toegeven dat ze ChatGPT gebruiken. Maar webhoster Strato kwam onlangs met een onderzoek naar buiten dat ons een idee kan geven.
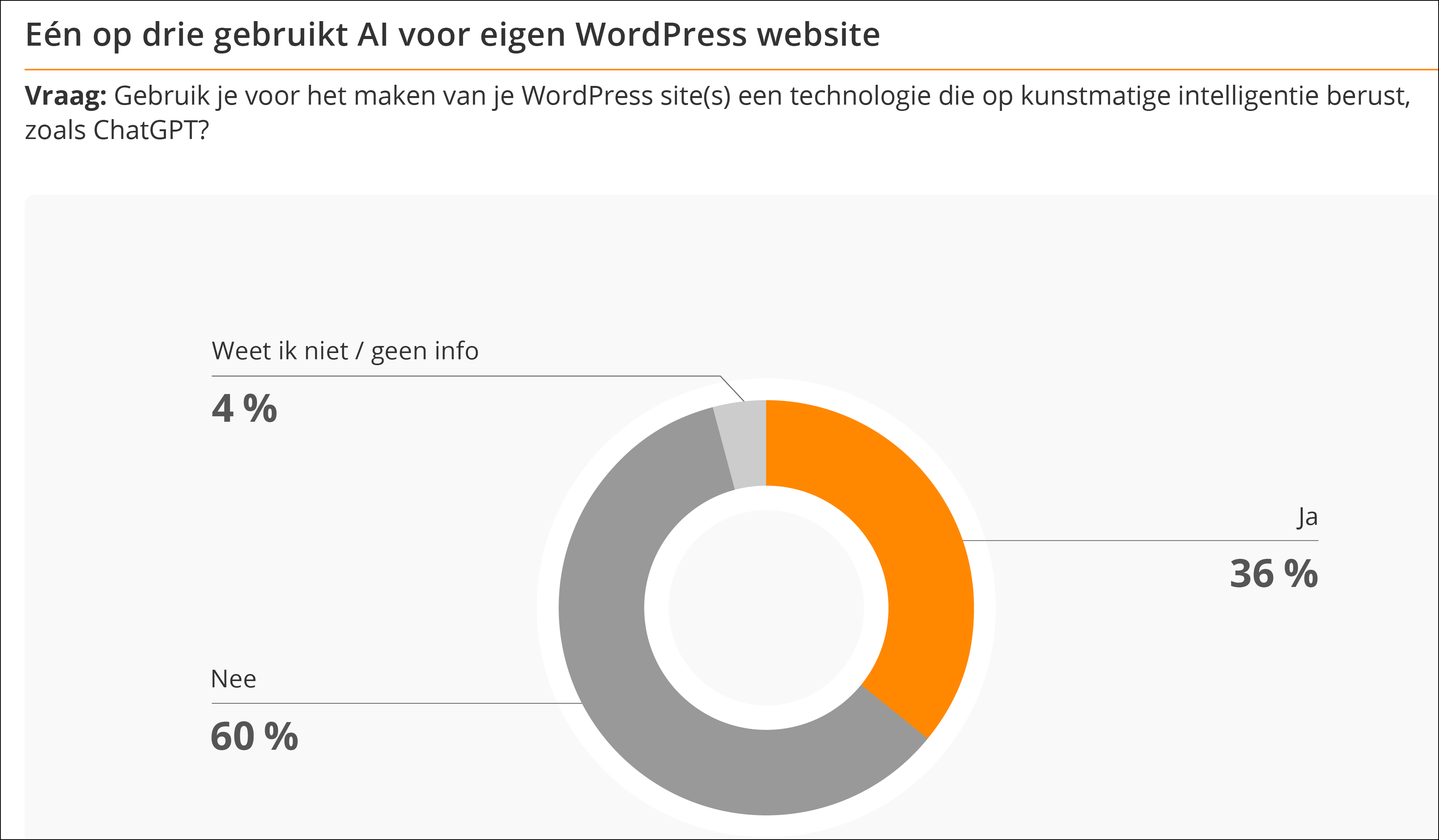
Strato liet door het Britse marktonderzoeksbureau YouGov een online enquête uitvoeren waarop 526 Duitsers met een eigen WordPress-website antwoordden. Daaruit bleek dat maar liefst 36 procent van de ondervraagden al ChatGPT en gelijkaardige tools actief inzet voor hun website. En 70 procent van die gebruikers zet de chatbot in om teksten voor hun website te schrijven, zoals een “Over ons”-tekst of een productbeschrijving, maar ook volledige blogartikels, FAQ’s (frequently asked questions) en zelfs juridische teksten. Ook voor het programmeren van websites wordt ChatGPT overigens ingezet.
Het gaat ook niet slechts om incidenteel gebruik, blijkt uit het onderzoek. 30 procent van de WordPress-beheerders die AI-tools gebruiken doen dat dagelijks, 41 procent meerdere keren per week en nog eens 21 procent één keer per week. Dat betekent dat maar liefst 92 procent van hen minstens één keer per week naar ChatGPT teruggrijpt voor hun website. Het gebruik van ChatGPT op het web zal volgens het onderzoek van Strato ook alleen maar toenemen. Van de niet-gebruikers kan 68 procent zich immers voorstellen om met AI-tools aan de slag te gaan voor hun website.
 |
|
Een op de drie WordPress-beheerders gebruikt |
Goedkoper en lagere kwaliteit
Hoewel veel van de websitebeheerders in de enquête door Strato waarschijnlijk met de beste bedoelingen ChatGPT inzetten, gebruiken anderen ze op grote schaal om één reden: het is goedkoop en er is dan ook geld mee te verdienen. Want daar zijn AI-tools heel goed in: goedkoop en op grote schaal teksten genereren. Waarom zou je dan nog uren besteden aan het schrijven van een diepgravend artikel als je het ook door ChatGPT kunt laten schrijven op basis van wat trefwoorden?
Die drang naar goedkope teksten begint problematische vormen aan te nemen. Zo bevatte Amazons Kindle-winkel tijdens de redactiesluiting al meer dan tweeduizend boeken waarbij ChatGPT als een van de auteurs werd vermeld. En er zijn er waarschijnlijk nog meer waarbij niet vermeld staat dat ze door een large language-model zijn geschreven. Je hoeft op YouTube ook niet lang te zoeken naar video’s die je uitleggen hoe je in enkele uren tijd een boek schrijft met de hulp van ChatGPT en je beloven dat je slapend rijk wordt.
Uiteraard is het resultaat niet zo kwalitatief, en de vrees is dan ook dat online boekenwinkels worden overspoeld door onzinboeken. Science-fictionpublicatie Clarkesworld Magazine kan ervan meespreken: in februari kondigde het aan dat het tijdelijk geen korte verhalen meer accepteerde omdat het op enkele weken tijd al meer dan 500 duidelijk niet door een mens geschreven verhalen kreeg ingestuurd.
Voor of tegen?
De moderators van Wikipedia zijn ook aan het discussiëren over het gebruik van ChatGPT om artikelen samen te vatten en zelfs met volledige artikelen voor de online encyclopedie te starten. Die moeten dan uiteraard nog nagelezen en aangepast worden door mensen, maar tegenstanders vrezen dat Wikipedia zo een groot aantal pagina’s zou krijgen over obscure onderwerpen die niet tijdig door mensen nagekeken kunnen worden en daardoor niet de vereiste kwaliteit hebben. Zo staat ChatGPT erom bekend dat het zelfs bronnen verzint. Er is een voorstel voor het gebruik van grote taalmodellen (https://en.wikipedia.org/wiki/Wikipedia:Large_language_models) op Wikipedia dat momenteel nog onder discussie is en alle voor- en nadelen beschrijft.
Die discussies tussen voor- en tegenstanders gaan vaak over dat conflict tussen kosten besparen en de kwaliteit hoog houden. Zo was Stack Overflow, de vraag-en-antwoord-site voor programmeurs, een van de eerste websites die het gebruik van ChatGPT om vragen te beantwoorden verbood. De moderators redeneerden: met ChatGPT is het gewoon té eenvoudig om grote hoeveelheden antwoorden te genereren die op het eerste gezicht juist zijn maar subtiele fouten bevatten. Het management van het bedrijf heeft sindsdien echter die ban tenietgedaan door de bewijslast over het gebruik van ChatGPT om te keren. Het bedrijf wil ook geld vragen voor het gebruik van de teksten op de website om taalmodellen te trainen en het is zijn eigen AI-tools aan het ontwikkelen. Terwijl de moderators blijven benadrukken dat de antwoorden van taalmodellen niet te vertrouwen zijn, wil het management er juist geld uit slaan.
Wie gaat er nog schrijven?
Google is al lang actief met AI en heeft zelfs de deeplearningarchitectuur Transformer uitgevonden waarop ChatGPT is gebaseerd. Maar toen ze werden opgeschrikt door de snelle groei van ChatGPT hebben ze snel allerlei plannen uit de doeken gedaan om ook taalmodellen toe te passen. Zo zou de zoekmachine er in de toekomst heel wat anders uitzien.
Momenteel is Google aan het experimenteren met boven de klassieke links naar webpagina’s ook samenvattingen te genereren van die webpagina’s om rechtstreeks een antwoord op de zoekvraag te tonen. De kwaliteit van die samenvattingen is niet al te best: zo bleek uit onderzoek door de website Tom’s Hardware dat een door Google samengevatte review van een laptop diverse eigenschappen van eerdere versies van de laptop besprak.
Maar het resultaat is natuurlijk dat veel mensen genoegen nemen met een samenvatting bovenaan en niet meer doorklikken naar de bronnen ervan. Die websites missen daardoor inkomsten en kunnen misschien geen mensen meer blijven betalen om het oorspronkelijke onderzoek te doen en te schrijven. Maar Google maakt wel gratis gebruik van hun werk en houdt bezoekers op de zoeksite om daar nog van advertentie-inkomsten te kunnen profiteren. Ook hier is de onderliggende strategie dus op grote schaal goedkoop teksten schrijven, met lage kwaliteit.
AI-trainen outsourcen naar AI
Generatieve AI-systemen zoals ChatGPT zijn niet alleen getraind op door mensen geschreven teksten. OpenAI betaalt ook mensen om de uitvoer van ChatGPT te beoordelen op correctheid en geschiktheid. Ontwikkelaars van AI-modellen gebruiken die aanpak al jaren, bijvoorbeeld op het platform Amazon Mechanical Turk (https://www.mturk.com).
Mensen krijgen daar taken zoals het oplossen van CAPTCHA’s, het labelen van foto’s of het beoordelen van teksten. Hun antwoorden worden gebruikt om AI-modellen te trainen. De deelnemers kunnen die taken van thuis uit online uitvoeren en worden daarvoor per opgeloste taak een klein bedrag betaald. Het is voor veel mensen uit lagelonenlanden een manier om een inkomen te verdienen, en voor anderen om wat geld bij te verdienen.
 |
|
Op Amazon Mechanical Turk besteden |
Die taken die ze moeten oplossen, zijn traditioneel moeilijk door computers uit te voeren. Maar als je betaald wordt per opgeloste taak, is het verleidelijk om AI-tools in te zetten om zoveel mogelijk taken te kunnen uitvoeren en zo meer te verdienen. Zouden vele deelnemers dat doen? Om dat uit te zoeken, zetten onderzoekers van het Zwitserse École polytechnique fédérale de Lausanne (EPFL) de taak op Amazon Mechanical Turk om extracten van zestien medische onderzoeksartikelen samen te vatten. Dan analyseerden ze de ingediende antwoorden op aanwijzingen van het gebruik van ChatGPT, zoals weinig variatie in de woordkeuze en het gebruik van copy/paste om tekst in te voeren. Van de 44 mensen die ze zo inhuurden, bleken volgens de onderzoekers naar schatting tussen de 33 en 46 procent ChatGPT te gebruiken (https://arxiv.org/abs/2306.07899).
Zonder mensen
Dat is natuurlijk problematisch. Want AI-modellen hebben al de neiging om fouten te maken. We hebben mensen nodig om de modellen te trainen, maar als we modellen massaal trainen op antwoorden van andere modellen, gaan de foute antwoorden zich voortzetten. De basis achter de modellen zal dan niet meer de menselijke expertise zijn, maar schattingen van andere modellen.
Als nu meer en meer mensen ChatGPT en andere taalmodellen gebruiken om teksten voor hun websites te schrijven, als nieuwswebsites redacteurs ontslaan omdat ze met taalmodellen sneller teksten kunnen produceren en als reviews en antwoorden op allerlei community-sites automatisch worden gegenereerd, gaan nieuwe taalmodellen meer en meer op niet-menselijke teksten worden getraind. Onze intuïtie zegt dat de kwaliteit van die modellen wel omlaag moet gaan. Maar is dat zo?
Britse onderzoekers bogen zich over die vraag en konden die bevestigend beantwoorden. Ze publiceerden hun resultaten in het artikel ‘The Curse of Recursion: Training on Generated Data Makes Models Forget’ (https://arxiv.org/abs/2305.17493). Hun conclusie? Het blijven trainen van grote taalmodellen op teksten die van het web worden gehaald, gaat mislopen wanneer veel van die teksten door AI-modellen zijn gegenereerd. Ze noemen dit fenomeen model collapse.
Taalmodellen storten in
De reden is eenvoudig. Elk model overschat waarschijnlijke gebeurtenissen en onderschat onwaarschijnlijke gebeurtenissen. De unieke teksten die wij mensen kunnen produceren, worden dus minder vaak door taalmodellen gegenereerd. Als je nu een taalmodel traint op tekst die is geproduceerd door een ander taalmodel, zijn de waarschijnlijke gebeurtenissen in die trainingsdata oververtegenwoordigd en de onwaarschijnlijke ondervertegenwoordigd.
Elk opeenvolgend taalmodel dat op de uitvoer van een vorig taalmodel wordt getraind, versterkt dus de waarschijnlijke gebeurtenissen en verzwakt de onwaarschijnlijke gebeurtenissen. Na enkele generaties van zulke trainingen hou je bijna niets van de oorspronkelijke menselijke invoer meer over. Het model is de oorspronkelijke trainingsdata voor een groot deel vergeten. De teksten die dit taalmodel genereert zijn dan ook volledige nonsens.
De onderzoekers ontdekten dat zelfs met nog tien procent menselijke trainingsdata de opeenvolgende generaties modellen uiteindelijk instortten. Het duurde dan alleen wat langer. En gezien AI-gegenereerde teksten zo goedkoop op grote schaal te creëren zijn, is de kans heel reëel dat we ooit met zo’n overwicht van AI-teksten te maken krijgen op het web. Hoe lossen we dat probleem dan op? Eén manier is volgens de onderzoekers om altijd een dataset met ‘propere’, gegarandeerd menselijke teksten bij te houden. Het model kan daar periodiek mee hertraind worden. Maar dan moet je altijd AI-gegenereerde van menselijke teksten kunnen onderscheiden, en bijna niemand labelt zijn teksten momenteel op deze manier. Bovendien zijn veel teksten deels door AI gegenereerd met een menselijke redactiestap erna.
 |
|
Taalmodellen trainen op tekst die door andere taalmodellen |
Waardeloze web
De mensen en bedrijven die nu snel zoveel mogelijk geld willen verdienen door goedkoop het web te spammen met door AI-modellen gegenereerde teksten, zullen dit inzicht waarschijnlijk weglachen. Maar op lange termijn zullen ook zij de gevolgen hiervan dragen. Hoe meer het web met AI-gegenereerde teksten wordt gespamd, hoe sneller onze AI-modellen die we daarop ![]() trainen zullen degenereren. En uiteindelijk zullen we dan verdrinken in middelmatige teksten en zullen we met onze AI-modellen niet meer boven die middelmaat kunnen uitstijgen. Het web wordt dan waardeloos. Is er nog tijd om deze ontwikkeling tegen te houden? Er is wel één lichtpuntje: door mensen geschreven teksten zullen in dit scenario goud waard worden…
trainen zullen degenereren. En uiteindelijk zullen we dan verdrinken in middelmatige teksten en zullen we met onze AI-modellen niet meer boven die middelmaat kunnen uitstijgen. Het web wordt dan waardeloos. Is er nog tijd om deze ontwikkeling tegen te houden? Er is wel één lichtpuntje: door mensen geschreven teksten zullen in dit scenario goud waard worden…