Overheden, onderzoeksinstellingen of bedrijven geven vaak om allerlei redenen ‘geanonimiseerde’ data vrij over personen. Helaas blijkt het in veel gevallen nog mogelijk om de personen achter de data te identificeren.
 Koen Vervloesem
Koen Vervloesem
Netflix doet er alles aan om zijn klanten films of series aan te raden die ze leuk vinden. Klanten krijgen suggesties op basis van hun eerdere waarderingen. Van 2006 tot en met 2009 (overigens in de tijd dat het bedrijf nog dvd’s verhuurde) organiseerde het de Netflix-prijs: een open competitie om een nieuw algoritme voor suggesties te ontwikkelen. Wie erin slaagde om tien procent betere voorspellingen te doen dan het algoritme van Netflix, kon één miljoen dollar winnen.
Deelnemers kregen een verzameling van honderd miljoen waarderingen die meer dan 480.000 willekeurig gekozen gebruikers gaven aan 18.000 films. Elk element van deze dataset was van de vorm <gebruiker, film, datum, waardering>, waarbij de gebruiker en film door een uniek ID werden voorgesteld, de waardering door een getal van 1 tot 5 en de datum was de datum waarop de gebruiker deze waardering gaf. De deelnemers aan de competitie konden hun algoritme trainen op de training-set, waarbij ze volledige toegang kregen tot de voorgaande gegevens.
 |
Netflix deed natuurlijk moeite om de privacy van zijn gebruikers met deze wedstrijd niet te bedreigen: de deelnemers kregen geen echte gebruikersnamen, maar anonieme id’s. Bovendien ging het slechts om een achtste van de volledige dataset. Netflix had de gegevens van bepaalde gebruikers zelfs bewust verstoord, bijvoorbeeld door waarderingen te verwijderen en fictieve waarderingen en datums in te voeren. Dit opdat gebruikers die op een of andere manier opvielen, toch niet geïdentificeerd konden worden door correlatie met externe gegevensbronnen.
Uiteindelijk bleken twee teams het algoritme van Netflix met meer dan tien procent te kunnen verbeteren. De winnaar kreeg de prijs van een miljoen dollar en Netflix kondigde aan dat het al aan een tweede competitie dacht, met ook demografische gegevens om nog accuratere voorspellingen te kunnen doen.
Geen tweede Netflix-prijs
Zover is het echter nooit gekomen. Al in 2007 slaagden onderzoekers Arvind Narayanan en Vitaly Shmatikov van The University of Texas in Austin er namelijk in om individuele gebruikers te identificeren door de ‘anonieme’ dataset van Netflix te correleren met filmwaarderingen op IMDB (Internet Movie Database). Ze publiceerden hun analyse in het artikel “Robust De-anonymization of Large Datasets” (https://arxiv.org/abs/cs/0610105).
De onderzoekers stelden zich de volgende vraag: hoeveel moet je van een Netflix-abonnee weten om zijn ID in de dataset te achterhalen en dus zijn kijkgeschiedenis te kennen? Dat bleek niet zo heel veel te zijn. Acht beoordelingen van films waarvan er twee helemaal fout mochten zijn en bijbehorende datums met een foutmarge van veertien dagen waren genoeg om 99 procent van de personen in de Netflix-dataset te identificeren.
Zo’n re-identificatie kan grote gevolgen hebben: mensen publiceren op IMDB publieke beoordelingen van sómmige films die ze bekijken en beseffen niet dat daardoor álle beoordelingen die ze privé dachten te doen in het Netflix-systeem ook bekend raken. Zo vonden de onderzoekers heel eenvoudig informatie over iemands politieke en religieuze opinies en seksuele voorkeuren terwijl in zijn publiek profiel op IMDB daarvan niets te vinden was.
De volgende keer dus dat iemand naar je favoriete films of andere persoonlijke informatie vraagt, antwoord je dus maar beter niet. Het lijkt misschien niet zulke gevoelige informatie, maar het maakt het wel gemakkelijker om je jou linken aan andere informatie die je wél liever verbergt.
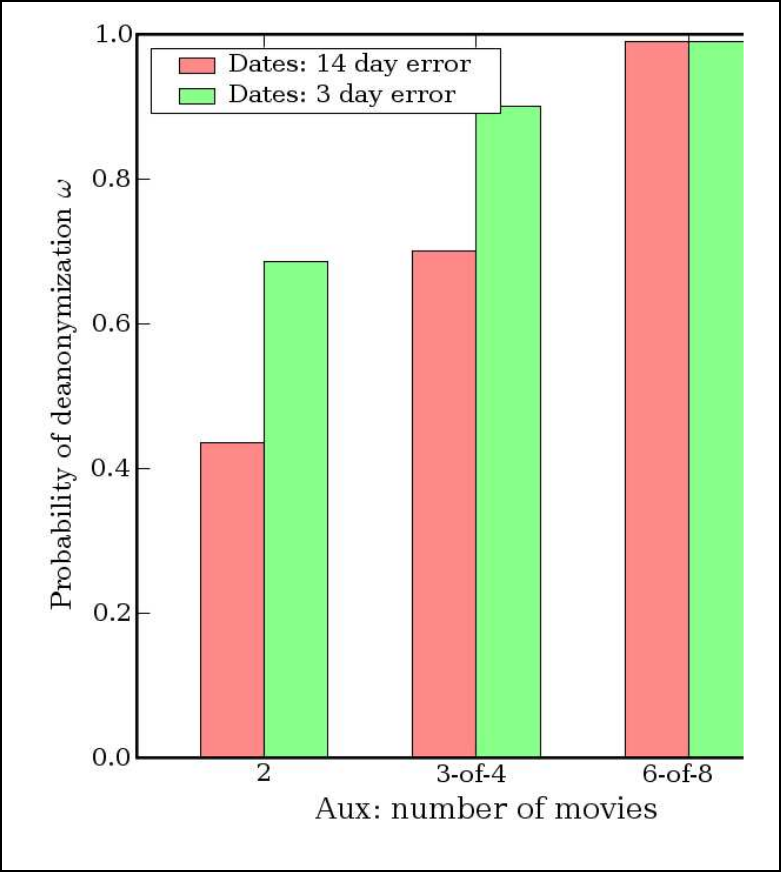 |
|
Iemand hoeft maar heel weinig informatie over je filmvoorkeuren te hebben |
Hoe meer gegevens, hoe gemakkelijker te identificeren
Ook al zijn de gegevens in de Netflix-dataset dus anoniem, een algemene regel in de wiskunde is: hoe groter een dataset, hoe meer patronen men erin kan vinden. Grote datasets betekenen dus meer kans dat er personen te identificeren zijn. In het licht van wat de onderzoekers van de universiteit van Texas vonden, werden de plannen van Netflix om een nog grotere dataset vrij te geven voor een tweede prijs dus op grote kritiek onthaald.
Ondertussen hadden enkele Netflix-gebruikers, waaronder een lesbische moeder die haar seksuele oriëntatie verborgen wilde houden, het bedrijf aangeklaagd, omdat het door de dataset vrij te geven een inbreuk op hun privacy beging. Netflix kwam een schadevergoeding overeen en besloot wijselijk om geen tweede competitie meer te organiseren en zo verdere juridische kosten te vermijden.
Bruikbaar of anoniem, nooit beide
Professor Paul Ohm van de University of Colorado Law School publiceerde in 2010 het veel geciteerde artikel Broken Promises of Privacy: Responding to the Surprising Failure of Anonymization (https://papers.ssrn.com/sol3/papers.cfm?abstract_id=1450006), waarin hij argumenteert dat privacywetten niet volstaan om deze re-identificaties tegen te gaan. Privacywetten beperken zich immers tot gegevens die jou persoonlijk identificeren.
In deze tijd van grootschalige databases en grote computerkracht is het echter kinderspel om gigantisch veel gegevens te combineren, te vergelijken en te correleren, waardoor je uit een combinatie van schijnbaar anonieme gegevens die volledig aan de privacywetten voldoen de identiteit van iemand kunt achterhalen.
Ohms voorstel was om niet meer toe te laten zulke grote databases in zijn geheel te analyseren, maar ze interactief te maken of alleen gemiddeldes over verschillende personen als resultaat terug te geven. Dat beperkt natuurlijk de bruikbaarheid van de gegevens, maar dat is juist zijn punt: gegevens zijn ofwel bruikbaar ofwel perfect anoniem, maar nooit beide. Geen enkele bruikbare database kan perfect anoniem zijn en hoe bruikbaarder de data gemaakt worden, hoe minder privacy de betreffende personen hebben.
 |
|
Een geanonimiseerde database bevat geen namen meer, maar in combinatie met andere gegevensbronnen zijn de personen alsnog te identificeren (bron: Paul Ohm) |
Geboortedatum en postcode
Zelfs met eenvoudige gegevens die in allerlei databases te vinden zijn, zoals een geboortedatum, postcode en geslacht, zijn veel mensen te identificeren. Dat bleek uit promotieonderzoek van informaticus Matthijs Koot van de Universiteit van Amsterdam. In 2012 verdedigde hij zijn proefschrift “Measuring and predicting anonymity” (https://pure.uva.nl/ws/files/1834030/107610_thesis.pdf).
Koot onderzocht van 2,7 miljoen Nederlanders gegevens uit de gemeentelijke basisadministratie (GBA). Daaruit bleek dat uit de combinatie van geboortedatum en de vier cijfers van een postcode twee derde van de Nederlanders uniek te herleiden zijn.
Als de overheid dus gegevens aan wetenschappelijke onderzoekers bezorgt die geanonimiseerd worden door de namen en burgerservicenummers te verwijderen, is dat geen voldoende garantie voor anonimiteit. Je hoeft immers de dataset maar te correleren met geboortedata en woonplaatsen op sociale media zoals Facebook om deze data in veel gevallen te herleiden naar de betreffende persoon.
Gsm-locaties de-anonimiseren
Iedereen die met een gsm rondloopt, weet dat telecom-aanbieders altijd onze locatie weten aan de hand van de locatie van de gsm-antenne waarmee we verbonden zijn. Deze datasets van gsm-locaties worden door de aanbieders geanonimiseerd en vervolgens aan bedrijven of overheidsdiensten verkocht om daar nuttige informatie uit te halen, bijvoorbeeld voor citymarketing, om verkeersproblemen op te lossen, enzovoort.
In 2013 bewezen onderzoekers Yves-Alexandre de Montjoye, César A. Hidalgo, Michel Verleysen en Vincent D. Blondel van het MIT en UCLouvain dat vier spatiotemporele punten in zo’n geanonimiseerde dataset voldoende zijn om 95 procent van de mensen te identificeren. Je hoeft dus maar vier tijdstippen te weten met de bijbehorende locatie van een persoon om in de geanonimiseerde dataset het volledige traject te reconstrueren van die persoon tijdens de hele duur van de registraties in de dataset, in dit geval vijftien maanden.
Als iemand tweets of foto’s met geo-lokalisatie online heeft staan, is het een koud kunstje om die persoon zo in de dataset te identificeren en zo alle locaties na te gaan waar hij is geweest. De details lees je in hun artikel “Unique in the Crowd: The Privacy Bounds of Human Mobility” (https://www.nature.com/articles/srep01376), dat ook vermeldt dat het met elf willekeurige spatiotemporele punten mogelijk was om iedereen in de dataset te identificeren.
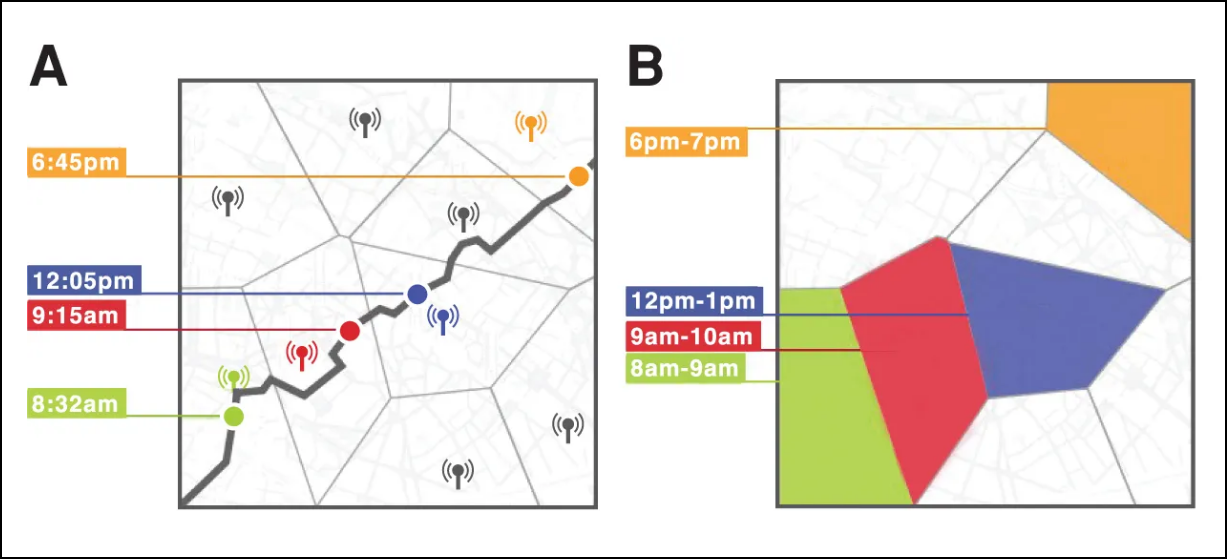 |
| De locaties van gebruikers van het gsm-netwerk (A) en hoe ze in een locatiedatabase van de mobiele provider kunnen worden opgeslagen (B) (bron: Yves-Alexandre de Montjoye, César A. Hidalgo, Michel Verleysen en Vincent D. Blondel) |
Pseudonimisering in de AVG
De AVG (Algemene verordening gegevensbescherming), die sinds 25 mei 2018 van kracht is, wil persoonsgegevens beschermen door te verplichten om er zorgvuldig mee om te gaan. De privacywet definieert onder andere de term pseudonimiseren als:
“het verwerken van persoonsgegevens op zodanige wijze dat de persoonsgegevens niet meer aan een specifieke betrokkene kunnen worden gekoppeld zonder dat er aanvullende gegevens worden gebruikt, mits deze aanvullende gegevens apart worden bewaard en technische en organisatorische maatregelen worden genomen om ervoor te zorgen dat de persoonsgegevens niet aan een geïdentificeerde of identificeerbare natuurlijke persoon worden gekoppeld”
We hebben het dus over pseudonimiseren als een set persoonsgegevens zo wordt getransformeerd dat de data niet rechtstreeks meer te herleiden zijn tot een persoon, maar dat de oorspronkelijke dataset met de juiste sleutel nog te reconstrueren is.
Identificeerbare eigenschappen zoals een naam of burgerservicenummer worden dan versleuteld in de gepseudonimiseerde dataset. De identificerende naam wordt dan getransformeerd tot een pseudoniem. Informatie over de persoon uit verschillende bronnen kan nog altijd worden gecombineerd, omdat de naam in al die bronnen tot hetzelfde pseudoniem wordt versleuteld.
Pseudonimisering versus anonimisering
Een gepseudonimiseerde dataset geldt volgens de AVG nog altijd als persoonsgegevens, zelfs al staan er geen identificeerbare eigenschappen meer in de dataset. Dat betekent dat op het bewaren van deze data of het delen ervan met andere partijen de privacywet van toepassing is. Pseudonimiseren geldt als beveiligingsmaatregel, die het privacy-risico voor de betrokken personen en de verwerker vermindert.
De privacywet definieert nergens de term anonimiseren, maar vermeldt deze wel. Het verschil tussen pseudonimisering en anonimisering is dat bij die eerste de oorspronkelijke (identificeerbare) data nog gereconstrueerd kunnen worden: met de sleutel waarmee de naam tot het pseudoniem getransformeerd is, kan het pseudoniem weer naar de naam getransformeerd worden. Het pseudonimiseren is dus omkeerbaar en daarom beschouwt de AVG gepseudonimiseerde gegevens nog altijd als persoonsgegevens.
We spreken van anonimiseren als identificerende eigenschappen een transformatie ondergaan die onomkeerbaar is. Eigenschappen worden bijvoorbeeld verwijderd, vervangen door een vaste waarde of vervangen door een willekeurige waarde. Omdat anonimiseren onomkeerbaar is, zijn geanonimiseerde data volgens de AVG geen persoonsgegevens meer en vallen die niet onder de privacywet. Dat is althans de theorie.
Onvolledige data de-anonimiseren
Hoe gemakkelijk is het om een willekeurige geanonimiseerde dataset te de-anonimiseren, zelfs als die dataset onvolledig is? Onderzoekers Luc Rocher, Julien M. Hendrickx en Yves-Alexandre de Montjoye van UCLouvain en Imperial College London stelden een model op om dat te voorspellen. Hun artikel “Estimating the Success of Re-identifications in Incomplete Datasets Using Generative Models” (https://www.nature.com/articles/s41467-019-10933-3) verscheen in 2019 in het tijdschrift Nature. Uit hun model blijkt dat je maar vijftien demografische eigenschappen nodig hebt om 99,9 procent van de Amerikanen te identificeren. En wie in een klein dorp leeft, heeft pech: is je woonplaats een van de eigenschappen in de dataset, dan zijn er maar heel weinig eigenschappen nodig om je te identificeren. Als je dan weet dat databrokers zoals Experian geanonimiseerde datasets met 248 eigenschappen per huishouden verkopen met gegevens van 120 miljoen Amerikanen erin, dan is het de vraag of we dit nog wel echt anoniem kunnen noemen.
De onderzoekers suggereren in hun artikel dan ook dat zelfs onvolledige en geanonimiseerde datasets waarschijnlijk niet voldoende zijn voor een bedrijf om zich aan de AVG te onttrekken: deze datasets zijn in de praktijk vaak nog altijd te de-anonimiseren, waardoor het om persoonsgegevens gaat die onder de privacywet vallen en waarmee dus heel behoedzaam moet worden omgesprongen.
Hoe dan wel anonimiseren?
Uit deze studies blijkt dus dat elke anonimisering van individuele gegevens gedoemd is om gede-anonimiseerd te worden. Er zijn sterkere garanties nodig. Zo zou je gegevens van verschillende personen kunnen samenvoegen en alleen deze geaggregeerde data in de dataset kunnen bijhouden.
Een andere oplossing is differentiële privacy (zie Denkwerk in PC-Active 307). Daarbij worden privacygevoelige gegevens van ruis voorzien en de gegevens van meerdere personen bij elkaar opgeteld om statistieken te berekenen. Op individueel niveau zijn personen dan niet meer te identificeren. Onder andere Privitar Lens (privitar.com/lens) werkt op deze manier en ook Google en Apple gebruiken differentiële privacy in sommige van hun producten.
Nog een andere aanpak is dat je een neuraal netwerk traint op identificeerbare gegevens en daarmee een synthetische dataset genereert die statistisch identiek is aan de originele dataset, maar op geen enkele manier meer tot individuele personen terug te leiden is. Maar dit toekomstmuziek. Kortom, anonimiteit is niet eenvoudig te bereiken.
