AI-toepassingen vereisen normaal een energieverslindende cpu of gpu met heel wat verwerkingskracht. Of kan dat toch anders?
 Koen Vervloesem
Koen Vervloesem
Onderzoekers hebben nu een techniek ontwikkeld om een neuraal netwerk na te bootsen in een slim ontworpen glasplaatje. Het resultaat? Het glasplaatje kan handgeschreven cijfers herkennen zonder energie te verbruiken en zonder complexe elektronica.
Neurale netwerken vormen de basis van allerlei toepassingen in AI (artificial intelligence). Ze bootsen de werking van de hersenen na, die een biologisch neuraal netwerk vormen: een kluwen van verbindingen tussen neuronen (hersencellen).
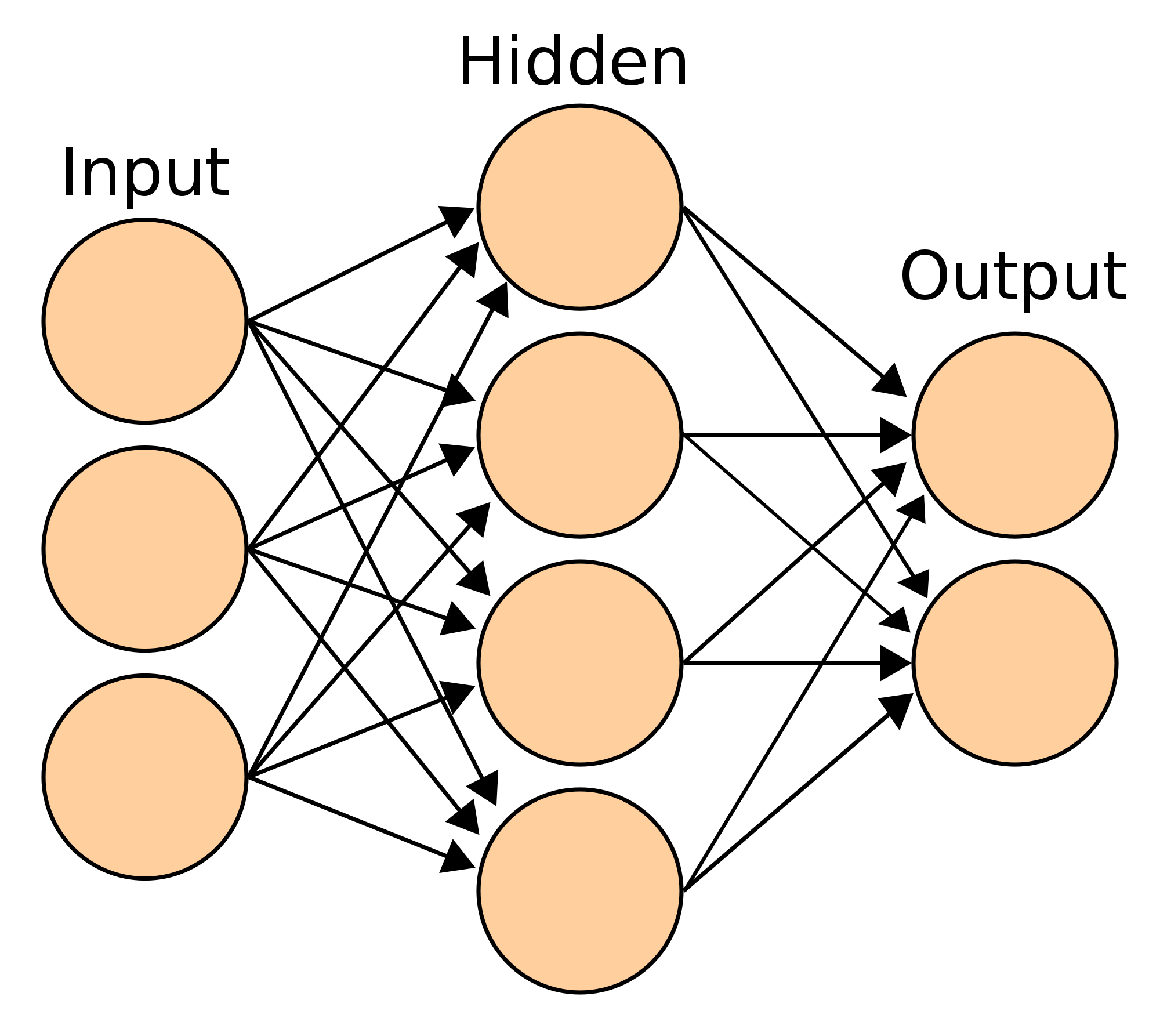
Een kunstmatig neuraal netwerk bestaat meestal uit meerdere lagen: een invoerlaag van neuronen die de invoer van een probleem voorstellen, een uitvoerlaag van neuronen die de oplossing van het probleem voorstellen, en één of meer tussenliggende lagen die berekeningen uitvoeren. Men spreekt van deep learning als het netwerk een groot aantal lagen tussen invoer en uitvoer heeft. Een populaire softwarebibliotheek voor neurale netwerken is TensorFlow (www.tensorflow.org), een opensourceproject dat door Google ontwikkeld is
 |
|
Een eenvoudig neuraal netwerk met een invoerlaag, uitvoerlaag en één tussenliggende laag |
Energieverslindende training
Een neuraal netwerk programmeer je niet door expliciet aan te geven hoe het een probleem moet oplossen; je ‘traint’ het door het vele voorbeelden van een probleem te geven, waardoor het uit zichzelf de taak leert. Dat trainen vraagt enorm veel rekenkracht, zeker in het geval van deep learning. Doorgaans gebeuren de berekeningen dan ook op zware cpu’s, gpu’s of gespecialiseerde microchips, die allemaal vrij veel energie verbruiken.
Computerwetenschappers van de University of Massachusetts onderzochten het energieverbruik van enkele bekende deeplearningnetwerken voor natuurlijke taalverwerking (https://arxiv.org/abs/1906.02243). Volgens hun schattingen stoot het trainen van het bekende model BERT op gpu’s evenveel uit als een trans-Amerikaanse vlucht. En dat is nog maar het begin. Een nieuw neuraal netwerk wordt talloze keren verfijnd voordat het gepubliceerd wordt en vaak doen onderzoekers heel veel moeite voor een 0,1% betere prestatie, zonder er bij na te denken dat die kleine verbetering voor een enorme extra -uitstoot zorgt. Uiteindelijk kan het productieklaar maken van één neuraal netwerk daardoor naar schatting evenveel uitstoten als vijf auto’s tijdens hun hele levensduur.
Eenvoudigere neurale netwerken
Als we willen dat het trainen van een neuraal netwerk minder energie verbruikt (de klimaatopwarming, weet je wel), dienen we het benodigde rekenwerk dus significant te verminderen. Maar dat betekent dat we onze neurale netwerken zo eenvoudig mogelijk moeten houden, in plaats van koste wat het kost het best presterende netwerk te zoeken.
Zo heeft het neurale netwerk VGG-16, momenteel een van de beste netwerken om foto’s te classificeren, heel veel lagen en 138 miljoen parameters van de neuronen. Daardoor vereist het ook 15,5 miljard bewerkingen om één foto van 224 bij 224 pixels te verwerken. Bij elke trainingsstap worden al die bewerkingen dus opnieuw uitgevoerd en al die parameters aangepast. Het is duidelijk dat dit veel energie verslindt. Maar het is niet eenvoudig om kleinere neurale netwerken te vinden die even goed presteren.
Energieverslindende toepassing
Nadat een neuraal netwerk getraind is, stopt het niet. Het netwerk wordt daarna immers in de praktijk toegepast, wat in het vakjargon inferencing (deductie) genoemd wordt. Stel dat je een neuraal netwerk voor gezichtsherkenning getraind hebt, dan bestaat de deductiestap eruit om in de dagelijkse praktijk het netwerk camerabeelden te laten analyseren en je te vertellen welke gezichten het herkent.
Ook de deductiestap verbruikt energie, en dat kan sterk oplopen als het continu gebeurt op bijvoorbeeld een videostream van een camera. Net zoals bij het trainen, gebeurt deze stap doorgaans op cpu’s of gpu’s. Afhankelijk van de toepassing wil je een snelle reactie en dan wordt er doorgaans zwaar geschut ingezet, bijvoorbeeld om realtime gezichtsherkenning te kunnen aanbieden. Hoe zwaarder de benodigde processorkracht, hoe meer energie er verbruikt wordt.
 |
|
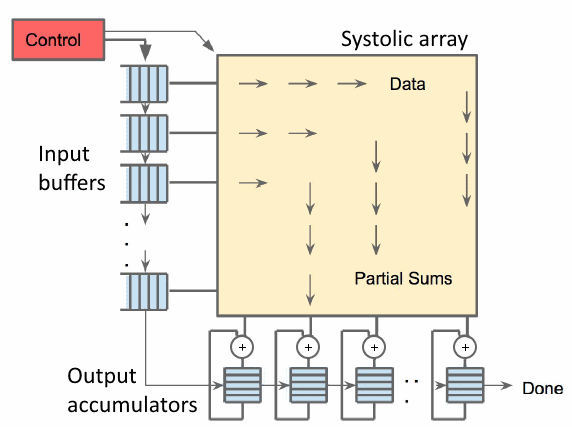
Vermenigvuldigen en delen in een specifiek patroon, dat is het enige wat de Edge TPU kan. |
Gespecialiseerde chips
Eén manier om de deductiestap van neurale netwerken energie-efficiënter uit te voeren, is om de netwerken te vereenvoudigen. Dat heeft Google gedaan door TensorFlow Lite (www.tensorflow.org/lite) te ontwikkelen, een versie van TensorFlow voor toestellen met beperkte mogelijkheden, zoals smartphones, Raspberry Pi’s of IoT-apparaten. In TensorFlow Lite moeten je neurale netwerken aan allerlei voorwaarden voldoen. Daardoor zijn de mogelijkheden beperkt, maar kan de deductiestap veel efficiënter gebeuren.
Bovendien heeft Google een chip ontwikkeld die geoptimaliseerd is om TensorFlow Lite-modellen uit te voeren: de Edge TPU (https://cloud.google.com/edge-tpu). Rond die chip heeft Google bovendien een hardwareversnellerbordje ontwikkeld, de Google Coral USB Accelerator (https://coral.withgoogle.com/products/accelerator). Dat kan tot 4 biljoen () bewerkingen per seconde uitvoeren en verbruikt daarbij slechts 2 W, wat je dus perfect met een 500 mA 5 V usb-poort kunt voeden. Een klassieke gpu verbruikt gemakkelijk een factor 100 meer… Dat is ook logisch: een gpu is niet ontwikkeld voor neurale netwerken, maar voor verwerking van grafische gegevens en voert dan ook talloze andere taken uit die energie verbruiken.
 |
|
De Google Coral USB Accelerator kan tot 4 biljoen bewerkingen per seconde |
Een andere aanpak
Maar het kan nog beter. Onderzoekers van de University of Wisconsin Madison, het Massachusetts Institute of Technology en Columbia University in New York vonden een verfrissende techniek om de deductiestap van neurale netwerken uit te voeren zonder enig energieverbruik. Hoe is dat mogelijk? Door niet gebruik te maken van elektronica, maar van optica…
In hun artikel Nanophotonic media for artificial neural inference (https://bit.ly/34ZP1NT) beschrijven de Amerikaanse onderzoekers hoe ze met een slim ontworpen glasplaatje een neuraal netwerk kunnen uitvoeren dat handgeschreven cijfers herkent.
Nanofotonisch neuraal medium
Dat werkt ruwweg als volgt. De informatie in bijvoorbeeld een beeld wordt gecodeerd in het golffront van het licht dat het glasplaatje binnenkomt. Het plaatje transformeert dan het golffront op zo’n manier dat het bijvoorbeeld cijferherkenning uitvoert. Aan de andere kant van het plaatje komt het licht dan naar buiten, geconcentreerd in de locatie die een cijfer voorstelt. Dit principe van beeldherkenning in glas kan al langer, maar niet voor zo’n complexe berekeningen en in zo’n klein volume glas.
De meeste bestaande optische neurale netwerken maken nog altijd gebruik van het klassieke model van een neuraal netwerk met lagen van neuronen: het licht komt aan de ene kant binnen en gaat door diverse lagen naar de andere kant. De Amerikaanse onderzoekers besloten om het anders aan te pakken. In hun nanofotonisch neuraal medium komt het licht ook aan de ene kant binnen en verlaat het de andere kant, maar ertussen kan het alle kanten uit reflecteren, bijvoorbeeld door luchtbelletjes, stukjes grafeen of gelijk welk materiaal dat een andere brekingsindex heeft dan het glas.
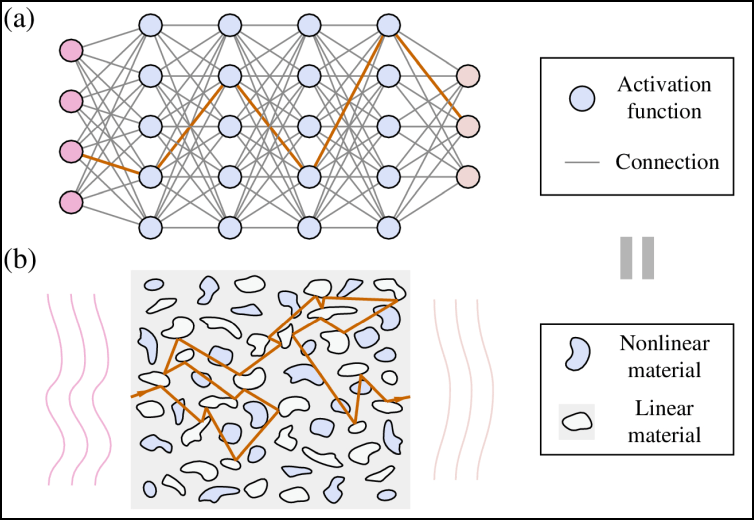 |
| In tegenstelling tot het klassieke neurale netwerk in (a) heeft het nanofotonisch neuraal medium in (b) geen lagen: het licht reflecteert alle kanten uit |
Glasplaatje trainen
Door te spelen met de vormen en plaatsen van deze onzuiverheden in het glas, kunnen de onderzoekers het binnenkomende licht in specifieke patronen laten reflecteren. In feite vormt de configuratie van het materiaal in het glas het equivalent van de parameters van de neuronen in een klassiek neuraal netwerk.
Dit aanpassen van de onzuiverheden komt overeen met de trainingsstap van de klassieke aanpak, waarbij de parameters van het neurale netwerk gekozen worden. Je begint hier dan met een glasplaatje met willekeurige stukjes onzuiverheden in en laat er het licht van verschillende handgeschreven cijfers op vallen. Je bekijkt op welke uitgangen het licht gefocust wordt en past stapsgewijs de onzuiverheden aan zodat het licht van een handgeschreven cijfer 2 zoveel mogelijk op uitgang 2 gefocust wordt, dat van het cijfer 8 op uitgang 8 enzovoort.
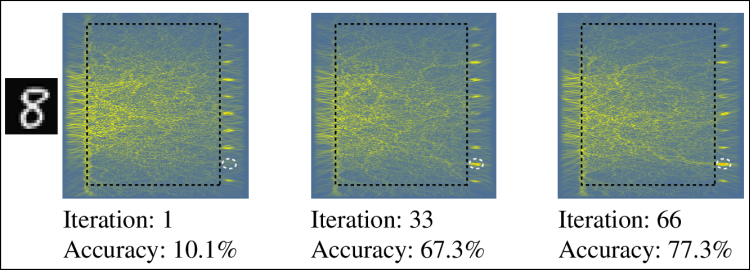 |
| Door stapsgewijs de configuratie van de onzuiverheden aan te passen, leert het glasplaatje steeds beter cijfers te herkennen |
Cijfers herkennen zonder energieverbruik
Na de training lieten de onderzoekers het licht van handgeschreven cijfers waarop het glasplaatje niet getraind was door het glas schijnen en registreerden ze de uitkomst. Uit de testverzameling van 1.000 cijfers herkende het plaatje 79% correct. Dat is nog niet zo schitterend, maar volgens de onderzoekers kan dit nog verbeterd worden door het glas groter te maken of de onzuiverheden minder beperkingen op te leggen.
In ieder geval werkt het herkennen van cijfers met deze aanpak zonder elektronica en is er geen energie nodig, buiten de beperkte lichtenergie. Het trainen deden de onderzoekers overigens niet met glas, maar door een simulatie van een glasplaatje in een computer. Er bestaat wel glasmateriaal dat je realtime kunt herconfigureren, wat mogelijk gebruikt kan worden in plaats van de (nog steeds energieverslindende) trainingsstap in een computer. Het moet ook nog blijken of een dergelijk glasplaatje onder realistische omstandigheden nog altijd even goede prestaties haalt. Maar het is duidelijk: er zijn nog veel mogelijkheden om AI energiezuiniger te maken. Hopelijk beginnen meer onderzoekers zich hierop te focussen in plaats van op die 0,1% betere prestaties…
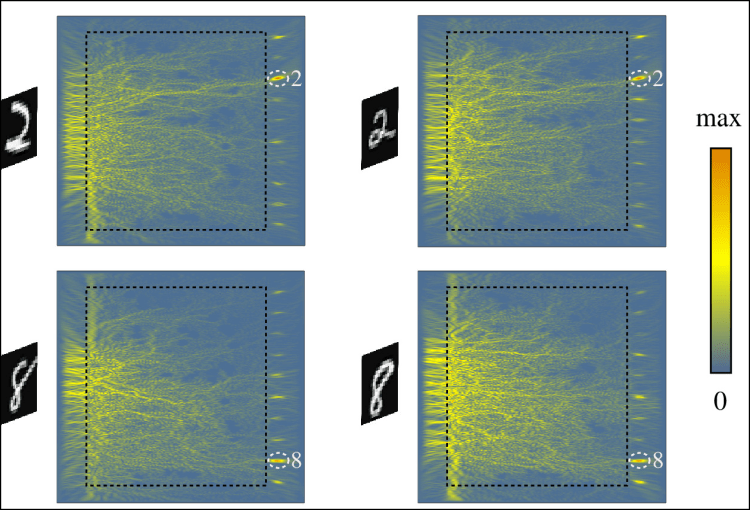 |
| Het licht van een handgeschreven cijfer wordt door onzuiverheden in het glasplaatje zo afgebogen dat het voornamelijk op één van de tien uitgangen geconcentreerd wordt |