Bedrijven zoals Apple en Google kunnen de gebruikerservaring alleen verbeteren als ze inzicht hebben in wat gebruikers doen. Dankzij differentiële privacy is dat mogelijk zonder inbreuk op je privacy.
 Koen Vervloesem
Koen Vervloesem
Met differentiële privacy krijgen de bedrijven krijgen statistische informatie over alle gebruikers, zonder dat ze informatie over individuele gebruikers hebben. Hoe werkt dat?
Bedrijven zoals Apple en Google zijn continu bezig met het verbeteren van hun producten. Maar daarvoor hebben ze gegevens nodig. Zo wil Apple bijvoorbeeld weten wat de populairste emoji’s zijn die gebruikers intypen. Een naïeve implementatie zou gewoon elke emoji die je intypt naar Apple doorsturen. Maar dat zou een inbreuk op je privacy zijn: welke emoji’s je intypt, zegt een boel over jou.
Privacy beschermen met ruis
Apple pakt het dus anders aan en gebruikt daarvoor technieken voor differentiële privacy: alle privacygevoelige gegevens worden voordat ze je apparaat verlaten van ‘ruis’ voorzien. Daardoor kan Apple niet exact meer zien wat je intypt: het is onmogelijk te weten te komen welke gegevens uit de ruis komen en welke je effectief ingetypt hebt.
Maar door alle gegevens met ruis van alle gebruikers te verzamelen en op te tellen, wordt de ruis, die willekeurig is, uitgemiddeld: bij de ene persoon zal een getal opgeteld zijn, bij de andere afgetrokken, en over het geheel genomen is de som daardoor ruwweg niet veranderd. Zo kan Apple nog altijd berekenen wat de populairste emoji’s zijn, zonder dat het weet welke emoji’s individuele gebruikers intypen en wat dus hun gemoedstoestand is.
Het gaat niet alleen om emoji’s: privacy is belangrijk in veel toepassingen. Zo gebruikt Google differentiële privacy in de Smart Reply-functie in Gmail om automatisch antwoorden op e-mails te suggereren. Die voorgestelde antwoorden worden berekend uit data van alle Gmail-gebruikers. Dan wil je natuurlijk niet dat één van je privéberichten plots opduikt in een gesuggereerd antwoord bij een andere gebruiker… Google garandeert door differentiële privacy dat dit niet gebeurt.
Ook zou je bijvoorbeeld een systeem voor machinaal leren kunnen trainen op medische dossiers van patiënten om artsen te helpen bij hun diagnose. Maar uiteraard wil je niet dat een willekeurige arts die dit systeem gebruikt gevoelige informatie over willekeurige patiënten waarop het systeem getraind is, te zien krijgt.
Hoe definieer je differentiële privacy?
De grote doorbraak in differentiële privacy kwam er in 2006 toen Cynthia Dwork, Frank McSherry, Kobbi Nissim en Adam Smith in hun artikel “Calibrating Noise to Sensitivity in Private Data Analysis”(https://bit.ly/2ZuTDbf) bewezen hoeveel ruis je dient toe te voegen om privacy te beschermen en een algemeen mechanisme voorstelden om differentiële privacy te bieden.
Maar wat bedoelen we precies als we zeggen dat een algoritme differentiële privacy biedt? Je zou bijvoorbeeld een algoritme kunnen ontwikkelen waarvoor de waarschijnlijkheid dat het een specifieke verzameling parameters leert, ruwweg hetzelfde blijft als we één individu veranderen in de verzameling waarop we het algoritme getraind hebben. Dat betekent dat we een individu kunnen toevoegen, verwijderen of eigenschappen van een individu kunnen aanpassen.
Als het algoritme deze eigenschap heeft, dan weten we dat één individu geen invloed heeft op wat het algoritme leert en dat we dus door vragen te stellen aan het algoritme op geen enkele manier informatie kunnen verkrijgen over een individu. Dan bereiken we differentiële privacy.
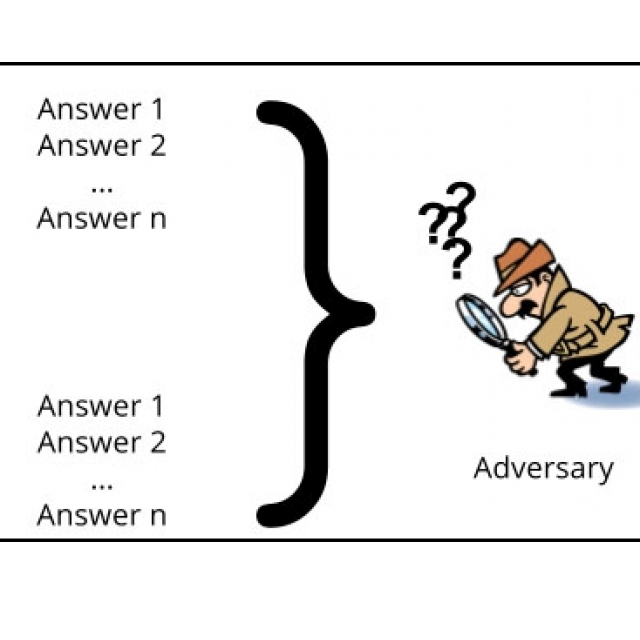
We spreken van differentiële privacy als de informatie met of zonder een gebruiker niet van elkaar te onderscheiden is
Paté
In de laatste jaren zijn er allerlei technieken voor differentiële privacy ontwikkeld. Zo kwamen onderzoekers van Google met Private Aggregation of Teacher Ensemble (PATE) (https://arxiv.org/abs/1610.05755). Het leuke van deze techniek is dat deze gewoon met bestaande modellen voor machinaal leren werkt. Als je een bestaand model, zoals een neuraal netwerk, neemt en daarop het PATE-framework toepast, krijg je een model dat bewijsbare privacy-eigenschappen heeft.
De intuïtie achter PATE is eenvoudig, leggen de onderzoekers uit op hun blog (http://www.cleverhans.io): als twee verschillende modellen, getraind op verschillende datasets zonder gedeelde individuen, hetzelfde antwoord geven op de vraag hoe een nieuw voorbeeld geclassificeerd dient te worden, dan onthult die informatie niets over de individuen in beide datasets.
In het andere geval is er wel een probleem: als twee modellen een verschillend antwoord geven, kan dit informatie lekken. Als de gegevens van Jan bijvoorbeeld slechts in het ene model gebruikt zijn en dat model voorspelt dat een patiënt die op Jan lijkt kanker heeft terwijl het andere model dat geen gegevens over Jan heeft het tegenovergestelde voorspelt, dan kunnen we daaruit afleiden dat de kans groot is dat Jan kanker heeft. Om dit soort gevolgtrekkingen onmogelijk te maken, dienen we ruis toe te voegen aan onze datasets.
Leraren
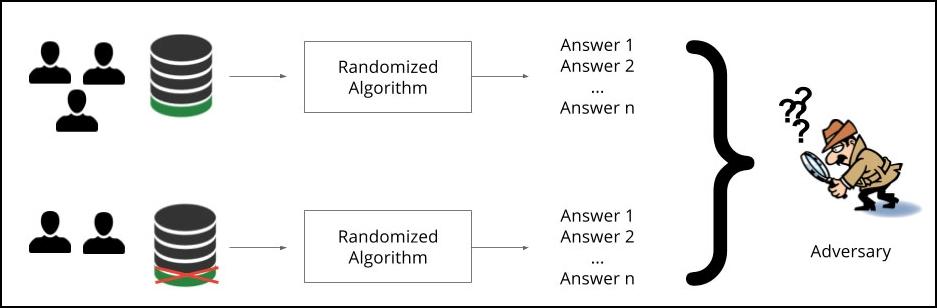
PATE begint dus door alle individuen waarover we gegevens hebben onder te verdelen in deelverzamelingen die geen enkele overlap hebben. Op elk van deze deelverzamelingen trainen we een model, dat de onderzoekers een ‘leraar’ noemen. Al die leraren doen dus hetzelfde, maar op een volledig verschillende verzameling gegevens.
Hoe classificeren we nu een nieuw voorbeeld met die ‘leraren’? Elke leraar geeft zijn beoordeling, en die worden allemaal opgeteld. Zo kan het dat drie leraren voorspellen dat iemand kanker heeft en één dat die persoon geen kanker heeft. Bij de verschillende uitkomsten wordt ruis toegevoegd, en daarna wordt de uitkomst met de meeste stemmen (inclusief de ruis) als voorspelling gegeven.
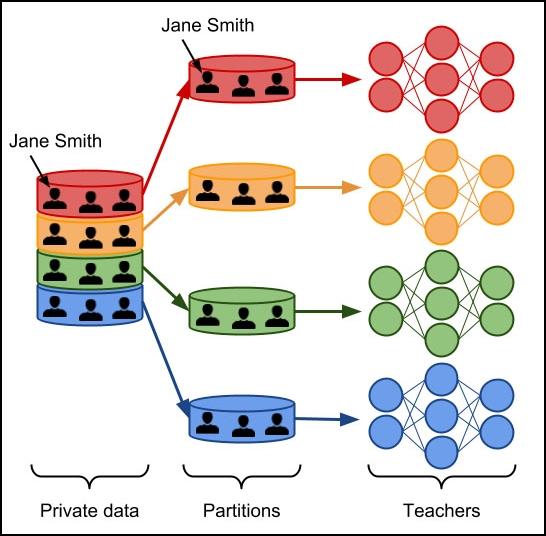
In PATE worden alle modellen op een volledig verschillende verzameling gegevens getraind
Dit werkt alleen maar als we de gebruikte modellen niet openbaren, anders kan iemand de interne parameters van de modellen bestuderen om hieruit informatie af te leiden over de individuen waarop ze getraind zijn. Maar een fundamenteler minpunt is: als we maar genoeg vragen stellen aan dit systeem, is de privacy van de individuen niet meer gegarandeerd. Het systeem moet daarom een maximaal aantal vragen opleggen, waarna we een nieuwe dataset van nieuwe individuen moeten opstellen en nieuwe modellen moeten trainen.
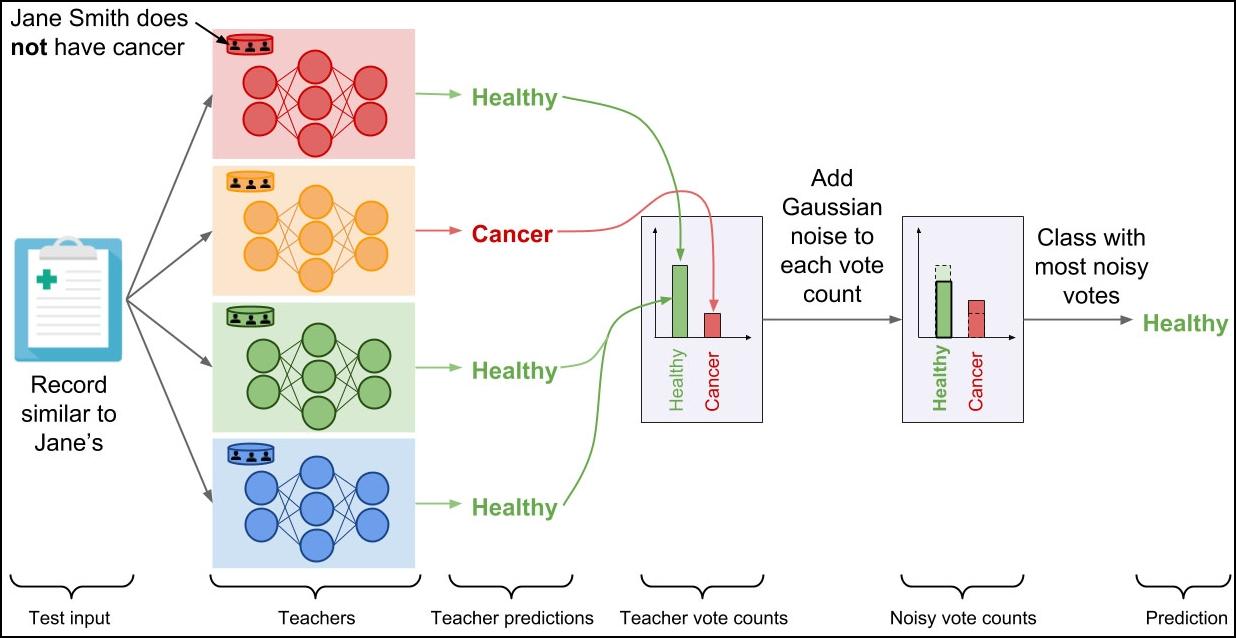
De voorspellingen van leraren worden opgeteld en met ruis verrijkt
om tot één voorspelling te komen
Leerling
Om deze twee nadelen op te lossen, is er in PATE een extra model toegevoegd: een ‘leerling’. De leerling selecteert gegevens zonder classificatie en voert die als invoer aan de leraren. Die beslissen gezamenlijk over een uitkomst met ruis, en de leerling gebruikt die uitkomsten om een eigen model te trainen.
Als dat model getraind is, gebruik je dit om voorspellingen te doen over nieuwe voorbeelden. De oorspronkelijke gegevens en zelfs de modellen van de leraren hoef je niet meer bij te houden: de leerling bezit alle kennis die we nodig hebben om nieuwe voorspellingen te doen.
Bovendien kun je het model van de leerling zonder vrees publiceren: iemand met toegang tot de interne parameters van de leerling kan in het slechtste geval de uitkomsten reconstrueren waarop de leerling getraind is, maar daaraan was na het optellen van de uitkomsten van de lerareb ruis toegevoegd. Op geen enkele manier kunnen we dus nog gevoelige gegevens afleiden over de individuen waarop de modellen van de leraren getraind zijn.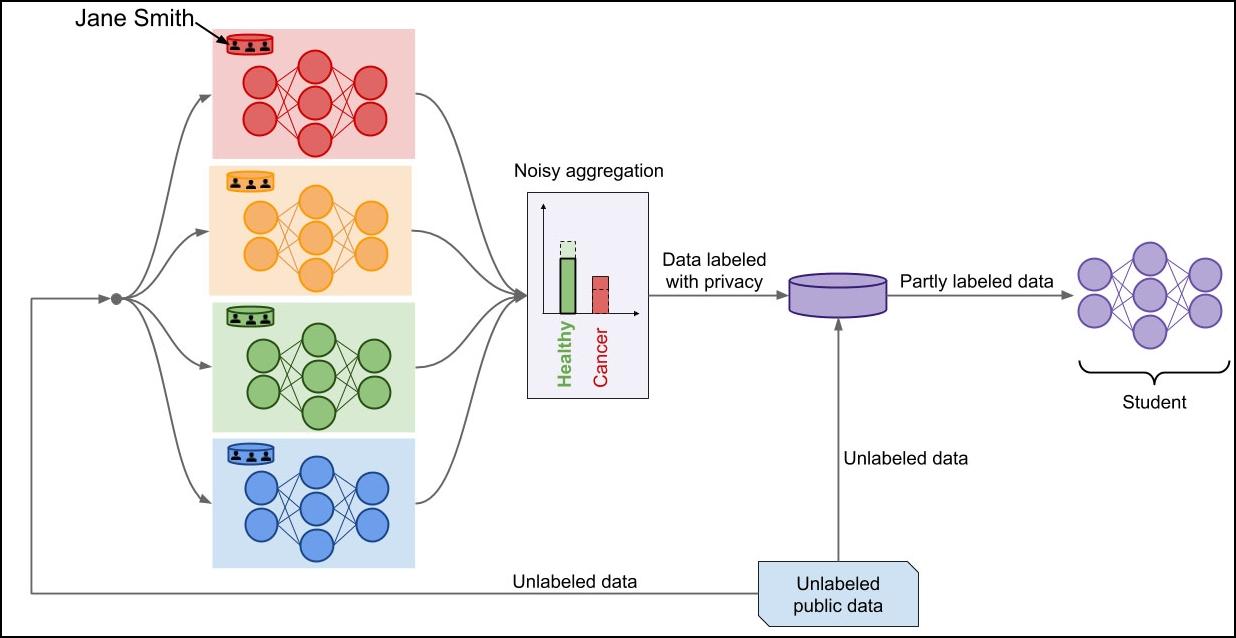
PATE werkt met ‘leraren’ en ‘leerlingen’ als modellen voor classificatie die je privacy beschermen
Betere modellen
Vaak hoor je dat er een tegenstelling bestaat tussen privacy en prestaties van AI-modellen: deze modellen zouden pas goed kunnen werken als ze heel veel data krijgen die je privacy in gevaar brengen. Maar de uitvinders van PATE ontdekten dat dit met hun framework helemaal niet zo is, zelfs integendeel.
Als de meeste leraren in het PATE-model immers dezelfde conclusie hebben over een nieuw voorbeeld, kunnen we veel vertrouwen hebben in de correctheid van de uitkomst: al deze leraren werden immers volledig onafhankelijk getraind op basis van volledig verschillende datasets. Door de werking van het PATE-model garanderen we dus niet alleen de privacy van de individuen, maar krijgen we ook een groot vertrouwen in de correctheid.
Dat is ook intuïtief te begrijpen, leggen de onderzoekers uit. Als we uit het model van een leraar specifieke eigenschappen van één individu uit de dataset te weten kunnen komen, betekent dat niet alleen een inbreuk op de privacy van dat individu, maar ook dat het model niet algemeen genoeg is om te generaliseren naar andere personen. In statistische termen noemen we dat overfitting: het model blijft te dicht bij de data die het kent en kan daardoor geen goede voorspellingen doen over data die het niet kent.
En verder
Er bestaan nog allerlei andere manieren om differentiële privacy te bereiken. Zo heeft Google na PATE nog een andere techniek ontwikkeld: Differentially Private Stochastic Gradient Descent (DP-SGD), waarvoor het ook een Python-bibliotheek als opensourcesoftware vrijgegeven heeft: TensorFlow Privacy (https://github.com/tensorflow/privacy). Elke ontwikkelaar die weet hoe je een neuraal netwerk met TensorFlow moet trainen, kan deze bibliotheek gebruiken om de privacy van gebruikers te waarborgen.
Het nadeel van al deze methodes voor differentiële privacy is wel dat de modellen geen gegevens zullen leren die maar één keer voorkomen. Dat zijn immers gegevens die specifiek voor één individu zijn en dat mag het model per definitie niet onthouden.
Apple heeft zelfs al expliciet toegegeven dat hun AI-algoritmes met differentiële privacy minder goede prestaties leveren dan mogelijk zou zijn als ze zich niet aan deze beperkingen zouden houden. Maar die prijs betaalt het bedrijf graag, omdat het zich dan op de borst kan kloppen dat het om de privacy van zijn gebruikers geeft. Sinds macOS Sierra en iOS 10 heeft Apple differentiële privacy in zijn besturingssystemen ingebouwd. En zo is privacy ondertussen zelfs een verkoopargument geworden, wat we alleen maar kunnen toejuichen…