IPFS (InterPlanetary File System) is voor het web wat BitTorrent voor downloads is: een peer-to-peer netwerk zodat je webpagina's niet van één plaats downloadt, maar verspreid van allerlei computers. Is IPFS de toekomst van het web?

Koen Vervloesem
IPFS (InterPlanetary File System) [1] is een peer-to-peer netwerk voor het web. Er zijn geen afzonderlijke servers en clients, maar als gebruiker van IPFS houd je het systeem mee in stand. Een website op IPFS heeft niet maar één server die pagina's aanbiedt, maar pagina's zitten over het hele netwerk verspreid, waardoor het systeem beschermd is tegen aanvallen zoals DDoS (distributed denial of service).
Wat is er mis met het web?
Voordat we uitleggen hoe IPFS werkt, staan we even stil bij waarom we een nieuw protocol voor het web zouden gebruiken. Wat is er mis met het web en hoe los je dat op?
Allereerst werkt HTTP (Hypertext Transfer Protocol), het protocol achter het web, niet efficiënt: als je een bestand op een website bekijkt, downloadt je computer dit bestand van één server. Voor een html-bestand lijkt dat niet zo erg, maar het geldt ook als je een videobestand downloadt. Jouw downloadsnelheid wordt beperkt door de uploadsnelheid van de server. Met IPFS daarentegen download je een bestand niet van één server, maar van meerdere tegelijk omdat de gegevens verspreid staan. Daardoor haal je hogere downloadsnelheden.
Je hebt dit zeker al eens meegemaakt. Je voegt een webpagina aan je favorieten toe en wilt die enkele maanden erna opnieuw bekijken. Maar dan blijkt de pagina niet meer te bestaan. Dat is schering en inslag op het web: de gemiddelde levensduur van een webpagina blijkt maar 100 dagen te zijn! Toen de dienst GeoCities in 2009 werd stopgezet, verdwenen zelfs in één keer maar liefst 38 miljoen pagina's van internet. IPFS daarentegen biedt een versiegeschiedenis van webpagina's aan, zodat je op elk moment in staat bent om naar een vorige toestand van een webpagina terug te keren. Ook als de website niet meer bestaat, want bij IPFS zijn de gegevens verspreid opgeslagen.
Het web begon als een gedecentraliseerd systeem dat het verspreiden en raadplegen van informatie democratiseerde. Iedereen kon een website opzetten en websites bezoeken. Intussen ziet het web er helemaal anders uit. De mogelijkheden zijn er in principe nog altijd, maar niemand doet het. Iedereen zit op Facebook, Instagram, Twitter en andere gecentraliseerde diensten. De bedrijven erachter censureren wat je erop plaatst en zo heeft een klein aantal bedrijven de controle over een groot deel van het web. IPFS verspreidt daarentegen de gegevens over meerdere computers, waardoor het web weer van iedereen is.
Door zijn te gecentraliseerde aanpak kan het web niet goed om met problemen zoals offline toegang, natuurrampen, verbindingen die gemakkelijk uitvallen of die te traag reageren enzovoort. IPFS daarentegen creëert veerkrachtige en zichzelf herstellende netwerken die zelfs tegen de moeilijkste omstandigheden kunnen.
IPFS is in allerlei
omstandigheden nuttig
Hoe werkt IPFS?
IPFS is een gedistribueerd bestandssysteem: gegevens zijn niet op één locatie opgeslagen, maar verspreid. Daarnaast is IPFS peer-to-peer: geen enkele aangesloten computer (een node) heeft meer privileges dan een andere: ze zijn allemaal gelijkwaardig. Elke node slaat op zijn eigen harde schijf gegevens op en wisselt die uit met andere nodes
Elke node heeft een publieke en een private sleutel, die lokaal opgeslagen zijn in versleutelde vorm. Een node identificeer je aan de hand van een hash van zijn publieke sleutel. Dat is zijn identiteit, en uit die hash kun je de publieke sleutel niet afleiden. Alle IPFS-nodes communiceren regelmatig met honderden andere nodes over het hele internet. Ze kunnen controleren of boodschappen niet verminkt zijn door een checksum te berekenen, een controlegetal om fouten op te sporen. En ze kunnen controleren of boodschappen wel komen van de node die beweert de boodschap te zenden. Dat gebeurt aan de hand van de publieke sleutel van de zender.
IPFS heeft ook een eigen routingsysteem. Dat kan enerzijds het ip-adres van een node met een specifiek ID opvragen en anderzijds de ID's opvragen van nodes die een specifiek object in hun bezit hebben. Objecten vraag je op via hun hash. Een node kan ook aan het netwerk signaleren dat het een object met een specifieke hashwaarde in zijn bezit heeft.
Geïnspireerd op BitTorrent
Een groot deel van het protocol van IPFS beschrijft hoe nodes gegevensblokken uitwisselen: BitSwap. Dit is geïnspireerd op BitTorrent. Elke node houdt een lijst bij van blokken die het heeft en blokken waarin het interesse heeft. Het grote verschil met BitTorrent is dat die blokken niet onderdeel van één bestand hoeven te zijn, maar elke oorsprong kunnen hebben.
Daarna 'onderhandelen' de nodes om blokken uit te wisselen. Als node A blokken heeft die node B nodig heeft en andersom, is dit eenvoudig: ze wisselen de blokken gewoon uit. Maar vaak heeft node A niet wat node B nodig heeft en/of andersom. Dan moeten de nodes werk verrichten om de blokken te krijgen waarin ze geïnteresseerd zijn. Node A zoekt dan bijvoorbeeld de blokken die node B wil hebben en wisselt die dan met B in voor de blokken waarin het zelf is geïnteresseerd. Deze aanpak spoort nodes aan om blokken waarin het zelf niet is geïnteresseerd, toch bij te houden.
Bestanden op krediet
Als een node op een moment geen blokken nodig heeft, zou hij kunnen beslissen om dan zelf ook geen nodes door te sturen naar nodes die wel blokken nodig hebben. Om deze nodes aan te sporen om toch blokken te delen, wordt er een grootboek bijgehouden met het aantal bytes dat er tussen elke twee nodes is uitgewisseld.
Als node A nu aan node B een blok vraagt, controleert node B eerst in het grootboek wat de 'schuld' is die node A aan node B heeft. Heeft A alleen maar blokken aan B gevraagd en nooit blokken aan B doorgestuurd? Dan beslist B waarschijnlijk om niet op de vraag van A in te gaan.
Hoe groter de schuld van A aan B, hoe lager de kans dat B op de vraag van A ingaat en het gevraagde blok stuurt. Het grootboek wordt gedistribueerd opgeslagen, net zoals bij de cryptomunt Bitcoin gebeurt in de blockchain.
Nadat nodes A en B een blok hebben uitgewisseld, passen ze hun lijst met blokken die ze hebben en blokken waarin ze geïnteresseerd zijn aan. Ze werken ook het grootboek bij om de uitgewisselde hoeveelheid bytes te registreren.
Nooit corrupt
Objecten in IPFS worden in een speciale structuur opgeslagen, een Merkle directed acyclic graph (Merkle DAG). Die structuur heeft een aantal voordelen. Zo is elk object uniek te adresseren met behulp van een checksum. Tegelijk kun je met die checksum verifiëren of er met het blok is geknoeid.
Met de Merkle DAG implementeert IPFS ook automatisch deduplicatie: alle objecten met dezelfde inhoud krijgen dezelfde checksum en worden dan ook maar één keer in IPFS opgeslagen. Dat spaart heel wat opslagruimte uit. Bovendien weet je altijd zeker dat je nooit objecten met een verschillend adres hoeft te vergelijken.
Namen
Wie aandachtig de uitleg over een Merkle DAG heeft gelezen, ziet onmiddellijk een probleem: als je iets aan de inhoud van een object verandert, verandert zijn adres. Hoe kun je dan naar een object verwijzen onafhankelijk van zijn inhoud? Daarvoor heeft IPFS de mogelijkheid toegevoegd om een naam aan een object te geven met het systeem IPNS (InterPlanetary Name Space).
Elke node heeft een namespace in de vorm /ipns/NodeID, waarbij NodeID het ID van de node is. De node kan een willekeurig object publiceren onder dit pad, ondertekend met zijn private sleutel. Als een andere node dit object ophaalt, kan het aan de hand van de publieke sleutel en het ID van de node controleren of de handtekening overeenkomt met het object.
Aan de slag
Om met IPFS aan de slag te gaan, download je go-ipfs [2]. De software bestaat voor Windows, macOS, Linux en FreeBSD. Onder Windows pak je het zip-bestand uit en plaats je het bestand ipfs.exe ergens in je pad. Open dan een Opdrachtprompt en test het uit met ipfs help. Daarna werkt IPFS op je computer.
Voer allereerst de opdracht ipfs init uit. Die opdracht initialiseert je node en genereert een RSA-sleutelpaar en bijbehorend ID. Je krijgt de vraag om een opdracht uit te voeren om een readme-bestand van het IPFS-netwerk te downloaden en te bekijken. Dat is direct al een test of je verbinding met IPFS werkt.
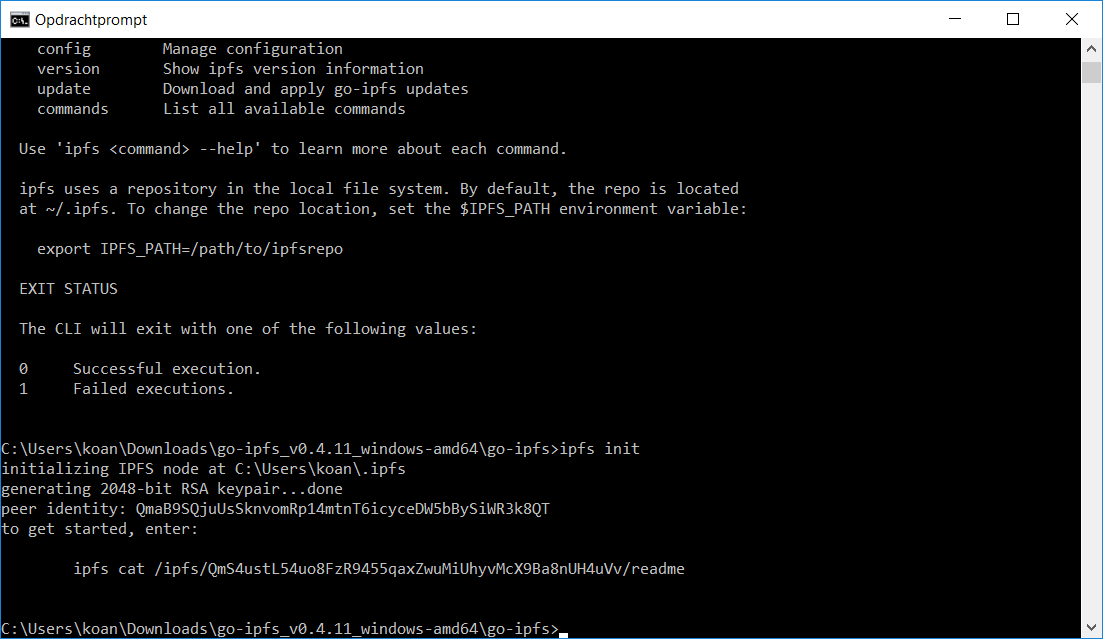
Bij de installatie genereert IFPS een sleutelpaar en ID voor je node
Het readme-bestand toont je ook de namen van enkele andere bestanden in dezelfde directory. De inhoud ervan krijg je te zien door een ipfs cat-opdracht beginnend met hetzelfde node ID als je voor het readme-bestand hebt gebruikt, maar dan met een andere bestandsnaam in plaats van readme, zoals about of quick-start. Vooral dit laatste bestand is interessant, omdat het je door een aantal voorbeelden leidt.
Je eigen website op IPFS
Je hebt tot nu toe met IPFS bestanden geraadpleegd, maar hoe publiceer je zelf iets op het InterPlanetary File System? Daarvoor draai je eigenlijk het best ipfs op een webserver, maar we tonen je hier voor de eenvoud hoe je het op je computer doet.
Start eerst IPFS als een daemon op de achtergrond met ipfs daemon. Plaats de website die je wilt publiceren in de directory website. Voeg daarna op een andere opdrachtprompt de bestanden toe aan het IPFS-netwerk met ipfs add -r website, waarbij je website vervangt door de naam van de directory waarin je webbestanden staan.
De laatste hash die de add-opdracht toont, is de hash van je website, laten we die HASH noemen. Als je nu in je webbrowser http://localhost:8080/ipfs/HASH bezoekt, krijg je je website te zien. De IPFS-daemon draait immers een privégateway op poort 8080 op je computer, die niet bereikbaar is buiten je netwerk.
Je kunt ook met een publieke gateway werken. Bezoek je bijvoorbeeld http://gateway.ipfs.io/ipfs/HASH, dan krijg je dezelfde website te zien. De gateway zoekt naar de hash in het netwerk, vindt de hash op je computer (of op een andere node die ondertussen het bestand heeft), vraagt die op aan je computer en zendt het bijbehorende bestand naar je webbrowser.
Er is nog één probleem: als je iets aan je website verandert, verandert de hash. En dus ook de url van je website... Daarvoor dient zoals we zagen IPNS. Met de opdracht ipfs name publish HASH publiceer je de HASH van je website onder een naam. Als je er geen opgeeft, zoals we hier doen, is die naam het node ID van je node. Als je nu http://gateway.ipfs.io/ipns/ID bezoekt, met je node ID, krijg je altijd je website te zien, ook wanneer je die verandert.
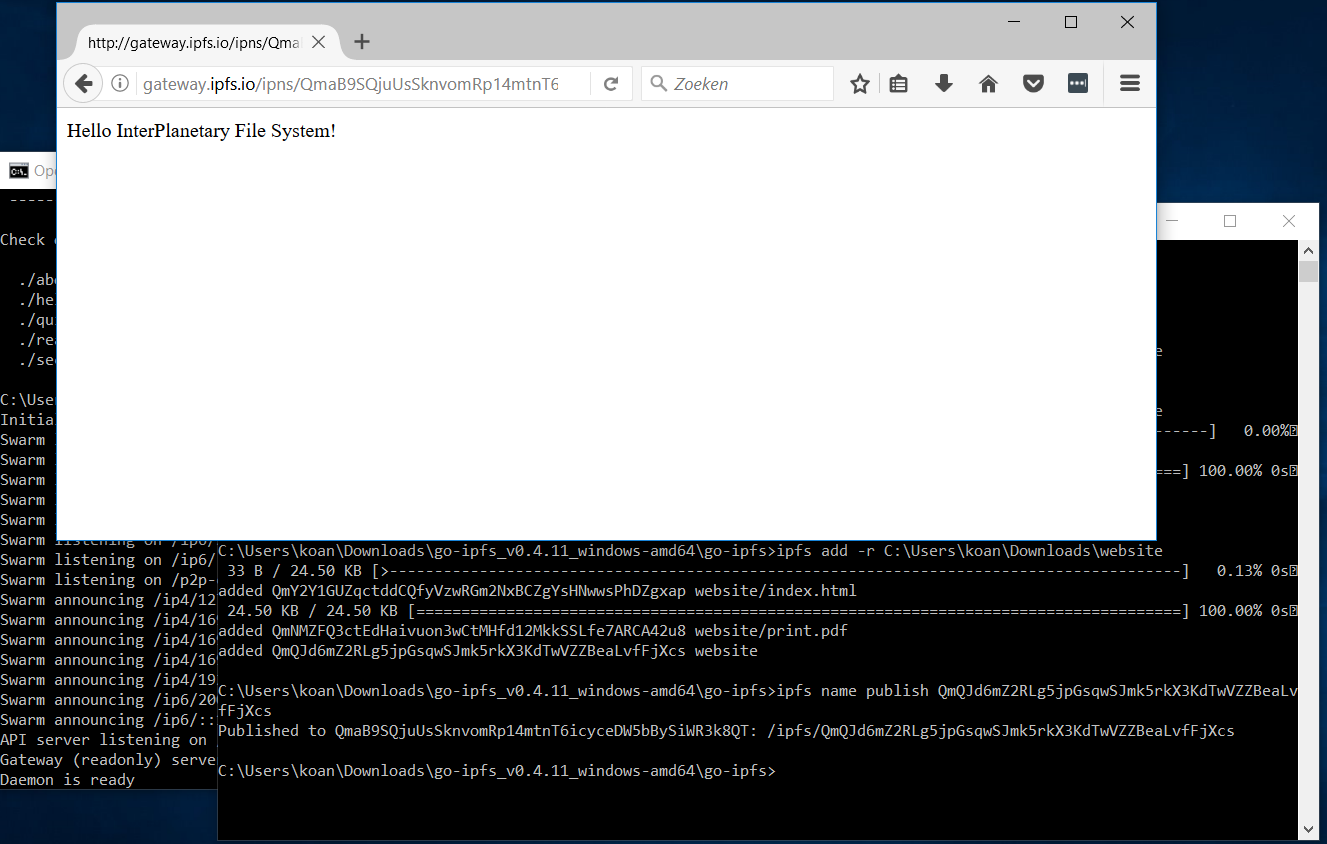
Een website op IPFS publiceren is snel gebeurd
En verder
Bekijk ook eens de webpagina http://localhost:5001/webui. Deze webconsole toont je onder andere met welke nodes je verbonden bent en welke bestanden je met IPFS deelt. De documentatie [3] geeft je meer uitleg over alle mogelijkheden van IPFS.
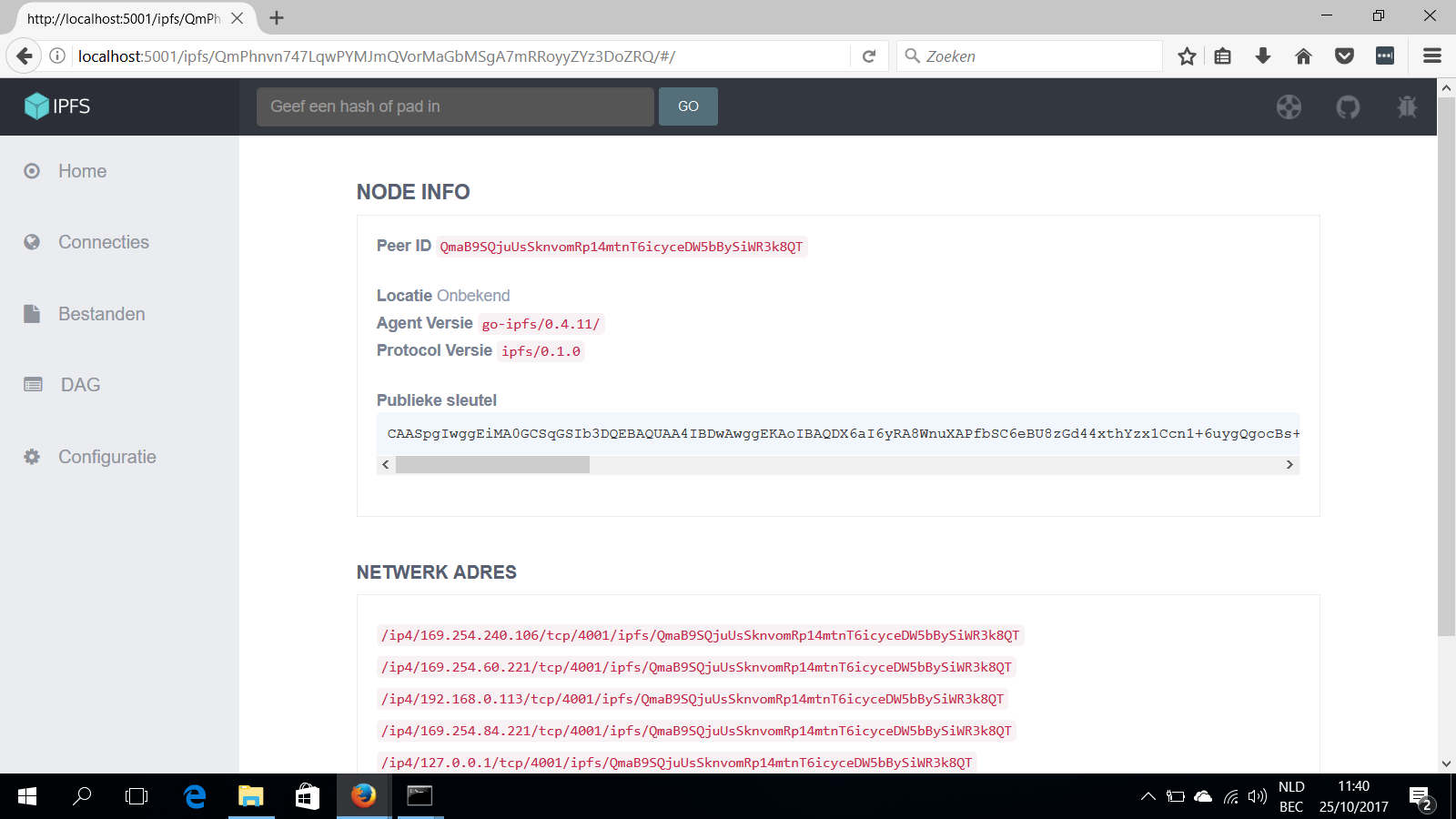
In de webconsole van IPFS vraag je allerlei informatie op
Infolinks
[1] https://ipfs.io/
[2] https://dist.ipfs.io/#go-ipfs