 In januari werd de AI-wereld opgeschrikt door DeepSeek-R1, een Chinees groot taalmodel. Het bleek vergelijkbare prestaties te leveren als de beste modellen van dat moment, maar aanzienlijk goedkoper. En dat ondanks de exportbeperkingen van de Amerikaanse overheid, waardoor DeepSeek niet over de beste hardware kon beschikken.
In januari werd de AI-wereld opgeschrikt door DeepSeek-R1, een Chinees groot taalmodel. Het bleek vergelijkbare prestaties te leveren als de beste modellen van dat moment, maar aanzienlijk goedkoper. En dat ondanks de exportbeperkingen van de Amerikaanse overheid, waardoor DeepSeek niet over de beste hardware kon beschikken.

Koen Vervloesem
De Verenigde Staten beschouwen zichzelf als de meest innovatieve natie ter wereld en willen die positie behouden. Daarom verbieden ze Amerikaanse chipbedrijven al jaren om hun krachtigste chips naar landen als China te exporteren. Hun redenering? Als China geen sterke AI-modellen kan ontwikkelen en de VS wel, behoudt die laatste zijn voorsprong of kan het die zelfs vergroten. Het feit dat AI ook voor militaire toepassingen ingezet kan worden, speelt eveneens een rol.
Het was dan ook voor velen een verrassing toen DeepSeek (https://www.deepseek.com) in het begin van 2025, ondanks deze exportbeperkingen, een sterk Large Language Model (LLM) wist op te leveren. Deze prestatie kwam echter niet uit het niets. DeepSeek is nog een jong bedrijf, opgericht in 2023, maar de geschiedenis gaat eigenlijk terug tot 2016. Toen richtte AI-onderzoeker Liang Wenfeng het hedgefonds High-Flyer (https://www.high-flyer.cn/en/) op, dat op de beurs handelde op basis van AI-modellen. Het bedrijf slaagde erin om 10.000 Nvidia A100-GPU’s aan te schaffen voordat de VS de verkoop hiervan aan China verbood.
In 2023 richtte High-Flyer een afzonderlijk lab op voor algemeen onderzoek naar AI, en dat werd DeepSeek. Al onmiddellijk begon het bedrijf modellen voor generatieve AI uit te brengen, die populair werden bij gebruikers die AI-modellen lokaal wilden draaien. Zo boden DeepSeek Coder en later DeepSeek Coder V2 hulp bij het programmeren, en kon DeepSeek Math wiskundige vraagstukken oplossen. Het bedrijf bracht ook algemene modellen uit, waarbij vooral DeepSeek-V2 en DeepSeek-V2.5 populair werden.
In december 2024 introduceerde DeepSeek dan zijn nieuwste model, DeepSeek-V3, en de maand daarop volgde DeepSeek-R1, dat speciaal getraind was op logische afleidingen, wiskundige redeneringen en het oplossen van problemen. Hoewel de meeste aandacht naar DeepSeek-R1 ging, zaten er ook grote innovaties in DeepSeek-V3. In deze Denkwerk bekijken we beide modellen.
DeepSeek-V3
De eerste versie van DeepSeeks model was, zoals veel modellen voor generatieve AI, sterk gebaseerd op Meta’s Llama. Gaandeweg voegden de onderzoekers diverse innovaties toe. Eén gebruikte techniek is mixture of experts (MoE). Daarbij wordt het model opgedeeld in verschillende kleinere modellen, ‘experts’ genoemd. Wanneer je dan een vraag aan het model stelt, worden verschillende tokens naar verschillende experts gestuurd. Zo bestaat het volledige model DeepSeek-V3 (https://arxiv.org/abs/2412.19437) uit 671 miljard parameters, maar voor elk token worden er maar 37 miljard geactiveerd.
Het DeepSeek-team heeft ook veel low-level-optimalisaties doorgevoerd om het model efficiënter te kunnen trainen. Dat was deels nodig omdat de onderzoekers door de Amerikaanse exportbeperkingen geen toegang hadden tot de krachtigste Nvidia-GPU’s. Ze moesten het doen met de Nvidia H800, een minder krachtige GPU, ontworpen voor de Chinese markt.
De onderzoekers lieten zich door die beperkte prestaties echter niet ontmoedigen en probeerden om het maximale uit de hardware te halen. Zo gebeuren berekeningen doorgaans met 32-bits kommagetallen, maar voor DeepSeek-V3 gebruikten ze 8-bits kommagetallen. Die berekeningen zijn minder nauwkeurig, maar verlopen sneller en verbruiken minder geheugen. Het bleek dat die hoge nauwkeurigheid niet nodig was. Het is de eerste keer dat deze techniek met succes werd toegepast bij het trainen van een groot model.
Daarnaast verlieten ze nog op een ander vlak de gebruikelijke paden. Ontwikkelaars gebruiken doorgaans de high-level-taal van Nvidia’s toolkit CUDA (Compute Unified Device Architecture) voor GPU-versnelling in hun toepassingen. Deze vertaalt de software naar PTX (Parallel Thread Execution), een low-level instructieset voor Nvidia’s GPU’s. Maar DeepSeek heeft een deel van zijn code rechtstreeks in PTX geschreven om deze te optimaliseren voor de specifieke hardware die ze gebruikten. Uiteindelijk heeft het team zo hun hele AI-model geoptimaliseerd rondom de beperkingen van de chips. De onderzoekers hebben hun model dan getraind op een corpus van 14,8 biljoen tokens. In tests bleek DeepSeek-V3 vergelijkbare prestaties te leveren als OpenAI’s GPT-4o en Anthropics Claude 3.5 Sonnet.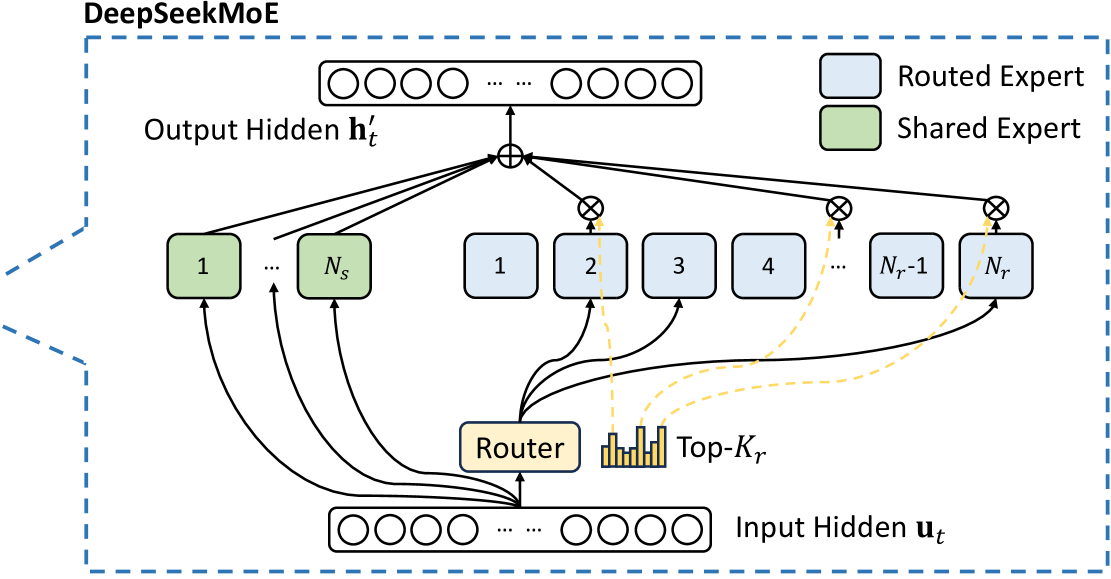
Met een “mixture of experts” (MoE) worden verschillende deelmodellen gecombineerd. (bron: DeepSeek)
DeepSeek-R1-Zero
De meeste aandacht ging echter uit naar DeepSeek-R1 (https://arxiv.org/abs/2501.12948), een zogenoemd Large Reasoning Model (LRM). Dit is in feite een Large Language Model, maar zo getraind dat het zijn eigen uitvoer kan evalueren en op die manier ook een soort gedachtegang en redeneervermogen toont. OpenAI introduceerde in september 2024 als eerste een LRM, o1, maar het bood dit model tegen een hoge kostprijs aan. DeepSeek-R1 bewees dat het goedkoper en efficiënter kon.
Normaal gesproken trainen onderzoekers dit redeneervermogen in een taalmodel door het te voorzien van voorbeelden van redeneringen, met dus zowel een vraag als een correct geacht antwoord. Dat vereist heel wat hulp van mensen, die deze voorbeelden moeten creëren. DeepSeek is er echter in geslaagd om een redeneermodel te trainen zonder menselijke tussenkomst in deze stap. Ze startten van het model DeepSeek-V3 en voegden tijdens het trainen redeneervragen toe in een prompt met een specifiek format, waarin werd gevraagd om het redeneerproces tussen de tags <think> en </think> te plaatsen en het antwoord tussen <answer> en </answer>.
De training werd gestuurd door beloningen voor nauwkeurigheid en het volgen van het voorgeschreven format. Dankzij de structuur waarin het antwoord tussen specifieke tags werd gezet, kon dit antwoord voor bijvoorbeeld wiskundevragen automatisch worden getest op nauwkeurigheid en werden correcte antwoorden zo beloond. Naast deze test op nauwkeurigheid werd ook getest of het model zijn redeneerproces wel tussen de juiste tags zette, met een beloning indien dat gebeurde.
Op deze manier ontwikkelde het model uit zichzelf redeneervermogens, zelfs complex gedrag waarvoor het niet expliciet werd beloond. Zo bleek het ook stappen terug te nemen om eerdere stapen te herzien en alternatieve benaderingen uit te proberen. Het resultaat van deze training was DeepSeek-R1-Zero, een krachtig LRM. Het nadeel was dat de uitvoer niet erg leesbaar was en vaak verschillende talen door elkaar gebruikte.
DeepSeek-R1
Daarom ontwikkelden de onderzoekers een tweede model, waarbij ze DeepSeek-V3 eerst trainden met behulp van enkele duizenden voorbeelden van redeneervragen en hun antwoorden in het gewenste format. Daarna onderging dit model dezelfde trainingsmethode als DeepSeek-R1-Zero, gestuurd met dezelfde beloningen voor nauwkeurigheid en het volgen van het format. Er werd nog een extra beloning toegevoegd voor het gebruik van slechts één taal.
Om de redeneervermogens verder te verbeteren, werden er zeshonderdduizend prompts en bijbehorende antwoorden van het model gegenereerd met een correct antwoord, en nog eens tweehonderdduizend uit DeepSeek-V3 die geen redeneervragen betroffen. Op die achthonderdduizend synthetische voorbeelden werd DeepSeek-V3 dan verder getraind. Het resultaat werd opnieuw gestuurd op nauwkeurigheid, format en eentaligheid voor redeneervragen, én deze keer ook op gewenste eigenschappen zoals behulpzaamheid en onschadelijkheid voor de vragen die niet over redeneringen gingen. Dat leidde uiteindelijk tot DeepSeek-R1, een bruikbare LLM met sterke redeneervermogens.
Kleine modellen leren redeneren
DeepSeek-R1 is een groot model, maar de onderzoekers hebben ook gekeken of ze kleinere modellen redeneervermogens konden bijbrengen. Ze namen daarvoor kleine versies van Alibaba’s Qwen en Meta’s Llama en trainden deze op de achthonderdduizend synthetische voorbeelden van DeepSeek-R1. Dit noemen we ‘gedistilleerde modellen’. Eigenlijk functioneerde DeepSeek-R1 hier als een ‘leraar’ om trainingsvoorbeelden te genereren waaruit de kleinere modellen dan leerden. Het resultaat? Ook deze kleinere modellen vertoonden na de training betere redeneervermogens. En omdat ze nog altijd kleiner zijn dan de volledige DeepSeek-R1, zijn ze efficiënter uit te voeren, sommige zelfs op normale consumentenhardware.
Maar wat als we nu op een normaal kleiner AI-model het hele trainingsproces uitvoeren dat gebruikt werd om tot DeepSeek-R1 te komen? De onderzoekers hebben dit uitgeprobeerd, onder andere met Qwen als basis. Het resultaat was verrassend: het krachtigere model via de synthetische voorbeelden distilleren tot een kleiner model leverde betere resultaten op dan het kleinere model trainen zoals het krachtigere model. De kleinere modellen ‘leren’ dus echt redeneervermogens van het grotere model.
Impact van DeepSeek-R1
De media richtten zich vooral op de uitspraak van DeepSeek dat ze maar 6 miljoen dollar nodig hadden om DeepSeek-V3 te trainen, terwijl GPT-4 van OpenAI naar verluidt 100 miljoen dollar zou hebben gekost. Er zijn wel vragen gerezen over of alle kosten in deze vergelijking in rekening genomen zijn. Maar het staat vast dat de low-level-optimalisaties het een efficiënt model om te trainen maken. En dat heeft andere ontwikkelaars van grote taalmodellen weer moed gegeven dat ze kunnen concurreren met de Amerikaanse big tech.
Zo hebben na de release van DeepSeek-R1 diverse andere ontwikkelaars op dit model voortgebouwd, gedistilleerde modellen van DeepSeek-R1 gemaakt of innovaties van DeepSeek in hun modellen geïmplementeerd. Vooral de grote Chinese bedrijven kwamen vrij snel met nieuwe taalmodellen. Zo introduceerde Alibaba het LLM Qwen2.5-Max (https://qwenlm.github.io/blog/qwen2.5-max/) dat beter presteerde dan DeepSeek-V3, en Tencent lanceerde zijn LRM Hunyuan T1 (https://tencent.github.io/llm.hunyuan.T1/README_EN.html) dat de concurrentie met DeepSeek-R1 zou aankunnen. Het heeft de ontwikkeling van AI-modellen duidelijk een boost gegeven./
 |
|
Tencents large reasoning model Hunyuan T1 lost met succes een wiskundig vraagstuk op |