Grote taalmodellen zoals ChatGPT zijn berucht om hun neiging om te ‘hallucineren’: ze geven regelmatig volledig verzonnen antwoorden. Hoewel hallucinaties nooit volledig zijn uit te sluiten, bestaan er wel technieken om ze te verminderen.

Koen Vervloesem
Toen OpenAI’s ChatGPT in november 2022 voor het grote publiek toegankelijk werd, waren gebruikers onder de indruk van de gesprekken die ze ermee konden voeren. Maar al snel bleek dat ChatGPT ook heel overtuigend onzin kon verkondigen. Wetenschappers die ChatGPT vroegen om een wetenschappelijk artikel te schrijven, merkten dat het taalmodel onbestaande referenties citeerde. Een advocaat die ChatGPT om hulp vroeg bij het voorbereiden van zijn zaak, liep tegen de lamp omdat hij zo verwees naar onbestaande gerechtelijke uitspraken. In beschrijvingen van bekende personen verzint het taalmodel vaak gebeurtenissen die nooit hebben plaatsgevonden. En stel je een vraag op basis van een premisse die helemaal niet waar is, dan gaat ChatGPT vaak vrolijk mee in je fictieve verhaal en doet er nog een schepje onzin bovenop.
Door hallucinaties kunnen we nooit volledig vertrouwen op de antwoorden van grote taalmodellen. Maar wat zijn dan mogelijke oorzaken van deze verzinsels? En kunnen we die hallucinaties verminderen door de oorzaken aan te pakken? Deze vragen houden onderzoekers al enkele jaren bezig, met als doel om grote taalmodellen met meer vertrouwen te kunnen gebruiken.
 |
|
Een vroegere versie van ChatGPT verzon boeken die de auteur van dit artikel geschreven zou hebben |
-
Trainingsdata
Grote taalmodellen worden getraind op grote hoeveelheden tekst. Als er in die tekst fouten of vooroordelen voorkomen, neemt het taalmodel die natuurlijk over. Bevat de trainingsset bijvoorbeeld teksten van een forum van complotdenkers, dan train je het taalmodel op de wildste theorieën, die het vervolgens als waar aanneemt. Daarom is het zo belangrijk dat de ontwikkelaars van het taalmodel de trainingsdata controleren en filteren op kwaliteit.
Een ander gevaar ligt in de eenzijdigheid van de data waarop een taalmodel is getraind. Als de dataset over bepaalde domeinen geen teksten bevat, zullen vragen in dit domein onvermijdelijk leiden tot antwoorden waarin het taalmodel de hiaten in zijn kennis opvult met verzinsels. Een groot taalmodel is immers maar een geavanceerde autocomplete. Het vervolledigt wat je vraagt, en zal zich altijd van die taak kwijten. Het zal nooit antwoorden dat het zijn taak niet kan uitvoeren.
Ook de manier waarop het taalmodel wordt getraind, beïnvloedt de neiging van het model om te hallucineren. Het is wat lastiger om hier duidelijke uitspraken over te doen, maar AI-onderzoekers hebben de laatste jaren heel wat ervaring opgedaan met de parameters die hier een invloed op hebben. Belangrijk om te weten is dat een model altijd wordt getraind om specifieke doelen te bereiken. Die trainingsdoelen moeten de feitelijkheid van het model ondersteunen en zo tot minder nonsensantwoorden leiden. Maar als een van de doelen bijvoorbeeld is om lange antwoorden te geven (mogelijk om te beknopte antwoorden te vermijden), kan dit bij feitelijke vragen waarvoor een kort antwoord voldoende is, leiden tot al te uitgebreide antwoorden met irrelevante toevoegingen. Dat vergroot natuurlijk de kans op hallucinaties.
-
Inferentie
Zelfs nadat het model is getraind, kunnen er nog verschillende zaken mislopen in de inferentiefase, dat is het moment dat je het model een vraag stelt en het zijn antwoordt genereert. Je kunt immers nog altijd allerlei parameters instellen die de antwoorden beïnvloeden. Een van die parameters is de temperature. Heeft deze een waarde dicht bij 0, dan produceert het taalmodel gefocuste en voorspelbare uitvoer. Ideaal dus voor feitelijke vragen, maar het resultaat kan dan ook wat saai en robotachtig overkomen. Hoe hoger de temperatuur, hoe creatiever en diverser de antwoorden. Dat kan voor sommige taken gewenst zijn, maar verhoogt ook het risico op hallucinaties. Als je tien keer dezelfde vraag stelt, krijg je dan immers tien keer een ander antwoord, niet alleen in formulering maar soms ook in betekenis.
Met de manier waarop je als gebruiker vragen stelt, beïnvloed je ook hoe feitelijk het taalmodel antwoordt. Je moet je er altijd bewust van zijn dat een taalmodel niet kan redeneren, maar uiteindelijk gewoon tekst genereert die statistisch gezien op je vraag aansluit. Als je dan een algemene vraag zonder context stelt, is de reeks van mogelijke vervolledigingen waaruit het taalmodel zijn antwoord genereert heel breed. Je kan dan totaal irrelevante en ook onjuiste antwoorden krijgen, of antwoorden die je vraag in een context interpreteren die je niet bedoelde. Het risico op hallucinaties verminder je door je vragen concreter te maken, te preciseren wat je verwacht, mogelijke dubbelzinnigheden uit te sluiten en context te geven. Die context kan ook in de vorm van een document met nuttige informatie. Tegenwoordig kan ChatGPT ook gebruikmaken van zoektochten op het web, wat hallucinaties vermindert.
Een populaire manier is Chain-of-Thought Prompting. Hierbij geef je een voorbeeld van een redenering in stappen aan het taalmodel, waarna je een vraag stelt met het verzoek om voor het antwoord ook in stappen te redeneren. Het taalmodel zal dan in redeneerstappen antwoorden en als neveneffect minder snel de neiging hebben om te hallucineren. Een vergelijkbare aanpak is Chain-of-Verification. Daarbij stel je een vraag, waarop het taalmodel een initieel antwoord creëert. Het model stelt dan aan zichzelf enkele vragen om zijn initiële antwoord te verifiëren op correctheid. Op basis van de antwoorden op die vragen geeft het dan zijn finale antwoord op je vraag. Ook deze aanpak vermindert hallucinaties, zo blijkt uit onderzoek gepubliceerd in “Chain-of-Verification Reduces Hallucination in Large Language Models” (https://arxiv.org/abs/2309.11495).
-
AI-ondervrager
Maar zelfs met al deze maatregelen blijven taalmodellen nog hardnekkig hallucineren. Onderzoekers zijn daarom aan het experimenteren gegaan met allerlei andere mogelijke oplossingen. Computerwetenschappers van de University of Oxford publiceerden vorig jaar een artikel in Nature, “Detecting hallucinations in large language models using semantic entropy” (https://www.nature.com/articles/s41586-024-07421-0), waarin ze zich focusten op één type hallucinaties, namelijk verzinsels. Dat is wanneer een taalmodel een bewering maakt die niet alleen verkeerd is, maar ook willekeurig (dus niet omdat het is getraind op foute gegevens).
Hun methode werkt door eenzelfde vraag meermaals aan het taalmodel te stellen, en de verschillende antwoorden te clusteren volgens hun betekenis. Als je zo op de vraag “Waar ligt de Eiffeltoren?” antwoorden krijgt als “De Eiffeltoren ligt in Parijs.”, “In de hoofdstad van Frankrijk, Parijs.”, “Parijs” enzovoort, maar ook “Berlijn” en “De Eiffeltoren ligt in Rome.”, dan geef je die antwoorden aan een ander taalmodel met de vraag om ze volgens hun betekenis te groeperen. Dat taalmodel zal dan de eerste drie antwoorden in één cluster samenbrengen en de andere als afzonderlijke clusters beschouwen.
Als nu alle antwoorden in dezelfde cluster vallen, ben je vrij zeker dat het antwoord geen verzinsels bevat. Als de meeste antwoorden in dezelfde cluster vallen en er één of twee afwijkende antwoorden zijn, ben je al iets minder zeker over het antwoord, maar kun je ervan uitgaan dat de hoofdcluster het juiste antwoord bevat. En als je meerdere clusters met een gelijkaardig aantal antwoorden hebt, dan is er veel onzekerheid en kun je eigenlijk niet op de antwoorden vertrouwen.
Het voordeel van deze methode is dat het systeem geen gelabelde voorbeelden van verzinsels nodig heeft: het detecteert uit zichzelf of een vraag al dan niet tot verzinsels in de antwoorden leidt. Je kunt dit nu gebruiken om bijvoorbeeld een taalmodel te laten weigeren om een vraag te beantwoorden waarover het model te weinig zekerheid heeft. Het nadeel is dat dit leidt tot een hoger energieverbruik. Een groot taalmodel verbruikt sowieso al veel energie. Als je dan meerdere keren dezelfde vraag stelt, vermenigvuldigt het energieverbruik nog.
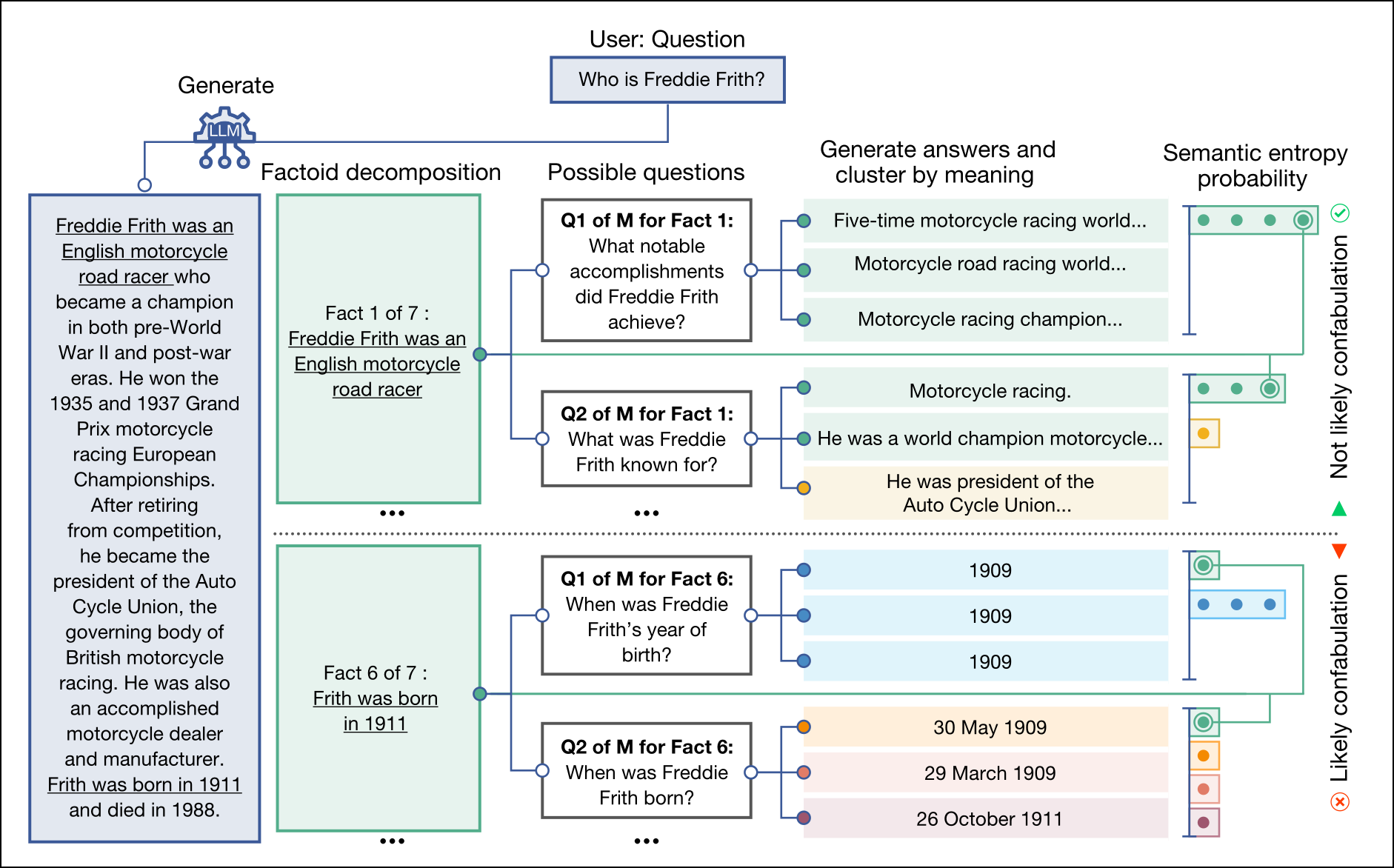 |
| Hoe diverser de betekenis van antwoorden op een vraag, hoe meer kans dat het om hallucinaties gaat |
-
Fundamentele beperking
Toch zullen taalmodellen altijd de neiging blijven hebben om te hallucineren. Onderzoekers van de National University of Singapore hebben in hun artikel “Hallucination is Inevitable: An Innate Limitation of Large Language Models” (https://arxiv.org/abs/2401.11817) een bewijs geleverd dat het onmogelijk is om hallucinaties in grote taalmodellen volledig te elimineren.
De onderzoekers definieerden daarvoor een formele wereld van berekenbare functies. In die wereld hallucineert een taalmodel dan als het er niet in slaagt om de uitvoer van een berekenbare functie te reproduceren. Ze bewezen vervolgens dat taalmodellen in die wereld onvermijdelijk met hallucinaties te maken krijgen, ongeacht de modelarchitectuur, leeralgoritmes, promptingtechnieken of trainingsdata. En die hallucinaties zijn niet beperkt: ze komen bij oneindig aantal vragen voor.
Omdat die formele wereld ook een deel is van de echte wereld, is dit resultaat ook van toepassing op die echte wereld. En omdat de taalmodellen in de formele wereld krachtiger en flexibeler zijn dan de taalmodellen in onze echte wereld, en het dus bewezen is dat zij onvermijdelijk hallucineren, zullen de minder krachtige taalmodellen in onze echte wereld dat ook doen.
Dit betekent dat elke methode die op taalmodellen vertrouwt om hallucinaties in taalmodellen te verminderen, zoals Chain-of-Thought en Chain-of-Verification, nooit hallucinaties volledig kan elimineren. En dat verklaart waarom taalmodellen zelfs eenvoudige taken vaak niet correct tot uitvoering kunnen brengen. Vraag bijvoorbeeld maar eens om alle tekenreeksen van X aantal tekens met alleen de letters “a”, “b” en “c” te generen. Elk taalmodel zal vanaf een bepaalde X hier niet meer in slagen. En dat is een fundamentele beperking. We kunnen dus alleen op grote taalmodellen vertrouwen als er extra controles gebeuren op hun uitvoer.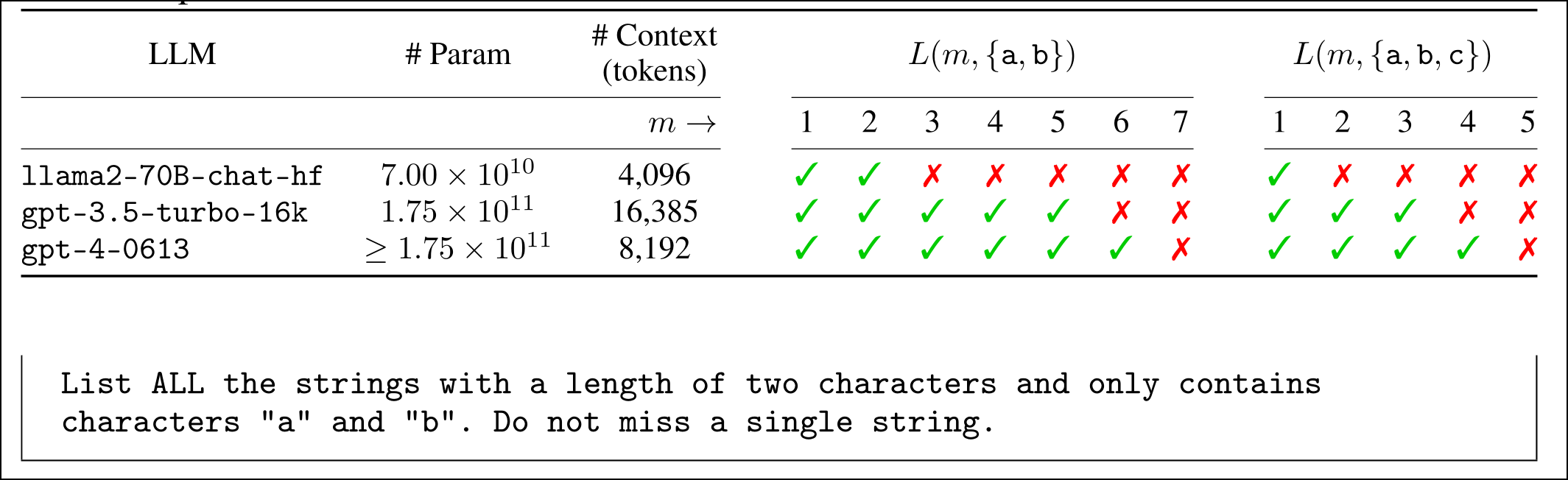
Elk taalmodel faalt vanaf een bepaalde lengte om alle combinaties met alleen de letters a, b of a, b en c te geven