Eind 2022 werd ChatGPT publiek beschikbaar. Twee jaar later is het effect van de AI-chatbot op ons taalgebruik al onmiskenbaar. Onderzoekers hebben in artikels op de medische website PubMed een opvallende toename gevonden van woorden als ‘delve’, ‘crucial’, ‘potential’ en ‘significant’. Hun verklaring? Het grote taalmodel van OpenAI wordt steeds vaker ingezet om teksten te (her)schrijven.

Koen Vervloesem
Heb je ook al gemerkt dat veel teksten tegenwoordig nogal overdreven dure woorden lijken te gebruiken? Als ik de laatste tijd op Twitter, LinkedIn of een blog iets lees, krijg ik steeds vaker de indruk dat ik met het lege gebeuzel van een zelfverklaarde zelfhulpgoeroe te maken heb.
AI-onderzoeker Jeremy Nguyen kon dit gevoel in harde cijfers omzetten. Hij deelde eind maart op Twitter een grafiek (https://x.com/JeremyNguyenPhD/status/1775846552088744106) over het gebruik van het woord ‘delve’ in teksten gepubliceerd op PubMed (https://pubmed.ncbi.nlm.nih.gov), een online archief van biomedische wetenschappelijke artikels.
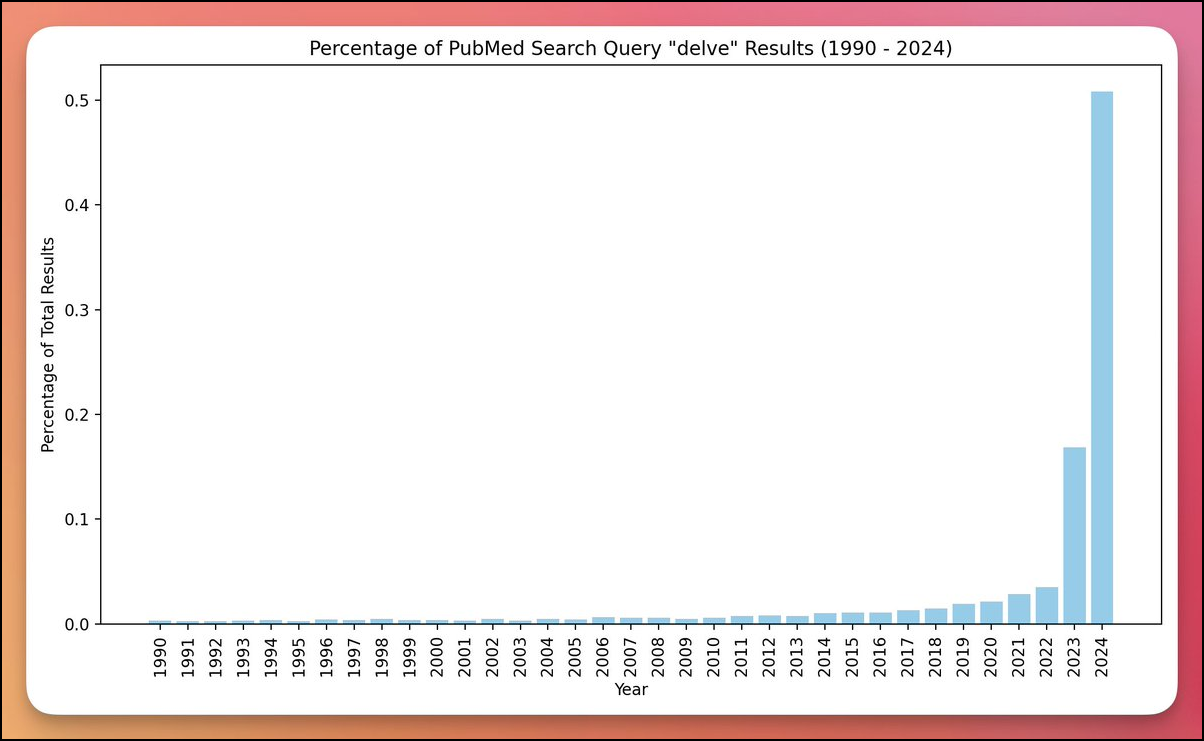 |
| Het gebruik van het woord ‘delve’ in biomedische artikels is geëxplodeerd in de laatste twee jaar (bron: Jeremy Nguyen) |
Nguyens theorie is dat de auteurs van veel van deze artikelen ChatGPT hebben gebruikt om hun teksten te (her)schrijven. Zijn ervaring (en die van velen) is immers dat ChatGPT een sterke voorkeur heeft voor het woord ‘delve’, evenals andere nogal bombastische woorden zoals ‘mosaic’ en ‘tapestry’. Hoewel er al langer een gestage toename van het gebruik ‘delve’ te zien is in zijn grafiek, is het opvallend hoe steil het gebruik toeneemt vanaf 2023, het eerste volledige jaar waarin ChatGPT publiek beschikbaar was.
Gewenst taalgebruik
Als je vaak teksten door ChatGPT laat genereren, begin je dit soort taalgebruik te herkennen. De teksten baden vaak ook in een overoptimistische sfeer en doen, afhankelijk van het onderwerp, gemakkelijk denken aan een onverholen marketingpraatje of het schreeuwerige geblaat van een zelfhulpgoeroe. Maar hoe komt dit? De gemiddelde tekst op internet hanteert toch niet dit taalgebruik? En is een groot taalmodel zoals ChatGPT niet getraind op grote hoeveelheden tekst van internet?
Dat laatste klopt, maar is niet het hele verhaal. Zoals we al in een eerdere Denkwerk hebben uitgelegd (zie PC-Active 333), gebruikt OpenAI de techniek Reinforcement Learning from Human Feedback (RLHF) om ‘gewenste’ antwoorden te verkrijgen. Het taalmodel wordt eerst getraind op grote hoeveelheden tekst van internet. Vervolgens geven mensen een score aan verschillende antwoorden van het model op diverse vragen, en met die scores wordt het model verder getraind zodat het de antwoorden geeft die de voorkeur van de mensen uitdragen. Vergeleken met de pure taalmodellen leveren deze InstructGPT-modellen (https://openai.com/research/instruction-following) volgens OpenAI betere resultaten op.
Terwijl het taalmodel oorspronkelijk gemakkelijk seksistische, racistische en gewelddadige antwoorden gaf, omdat het nu eenmaal op tekst was getraind die ook dat soort uitingen bevatte, slaagde OpenAI erin dankzij menselijke feedback deze ongewenste uitvoer te voorkomen. Maar mensen op deze taak zetten, kost veel geld. OpenAI en andere bedrijven die grote taalmodellen ontwikkelen, outsourcen dit dan ook vaak naar landen met lagere lonen, zoals Kenia en Nigeria.
Het spreekt voor zich dat dit een impact heeft op het taalgebruik dat als gewenst wordt beschouwd en dat ChatGPT dus overneemt. Technologiejournalist Alex Hern van The Guardian kwam met de theorie dat ChatGPT zo graag ‘delve’ gebruikt omdat het woord in professioneel taalgebruik in Nigeria veel frequenter voorkomt (https://www.theguardian.com/technology/2024/apr/16/techscape-ai-gadgest-humane-ai-pin-chatgpt) dan in de VS of Groot-Brittannië. De mensen in Nigeria die met RLHF feedback geven op teksten van ChatGPT, zouden op die manier onbewust hun eigen taalgebruik in de chatbot introduceren, waardoor het taalmodel zich ook lichtjes als een Nigeriaan gedraagt.
Overmatig woordgebruik
Dit is allemaal nogal anekdotisch. Onderzoekers van de universiteit van Tübingen (Duitsland) en de Northwestern University in Evanston, Illinois (VS) wilden daarom grondiger nagaan hoe wijdverspreid het gebruik van ChatGPT in academische teksten is. In hun artikel Delving into ChatGPT usage in academic writing through excess vocabulary (https://arxiv.org/abs/2406.07016) bespreken ze hun aanpak.
Hun idee is om te kijken naar ‘overmatig woordgebruik’ in teksten. Ze lieten zich daarvoor inspireren door het idee van ‘oversterfte’ tijdens de coronapandemie: hoeveel meer mensen stierven er tijdens de pandemie vergeleken met ervoor? Op dezelfde manier zetten ze zich aan de taak om te meten hoeveel meer specifieke woorden na de publicatie van ChatGPT werden gebruikt vergeleken met de jaren ervoor. Ze analyseerden met deze aanpak meer dan 14 miljoen samenvattingen van PubMed-publicaties in biomedische wetenschappen van 2010 tot 2024.
Voor elk woord berekenden ze in hoeveel artikels per jaar het voorkwam ten opzichte van het totaal aantal artikels gepubliceerd in dat jaar. Dat resulteerde in een frequentie van voorkomen. Bij sommige woorden nam die frequentie plots enorm toe in 2023 en 2024. Maar vaak was er al een zekere stijgende trend. Om dus te bepalen wat de extra toename van het woordgebruik was, berekenden de onderzoekers eerst met een lineaire interpolatie uit de frequentie in 2021 en 2022 wat de verwachte frequentie in 2023 en 2024 had moeten zijn, en namen ze dan het verschil met de gemeten frequentie als overmatig gebruik van dit woord.
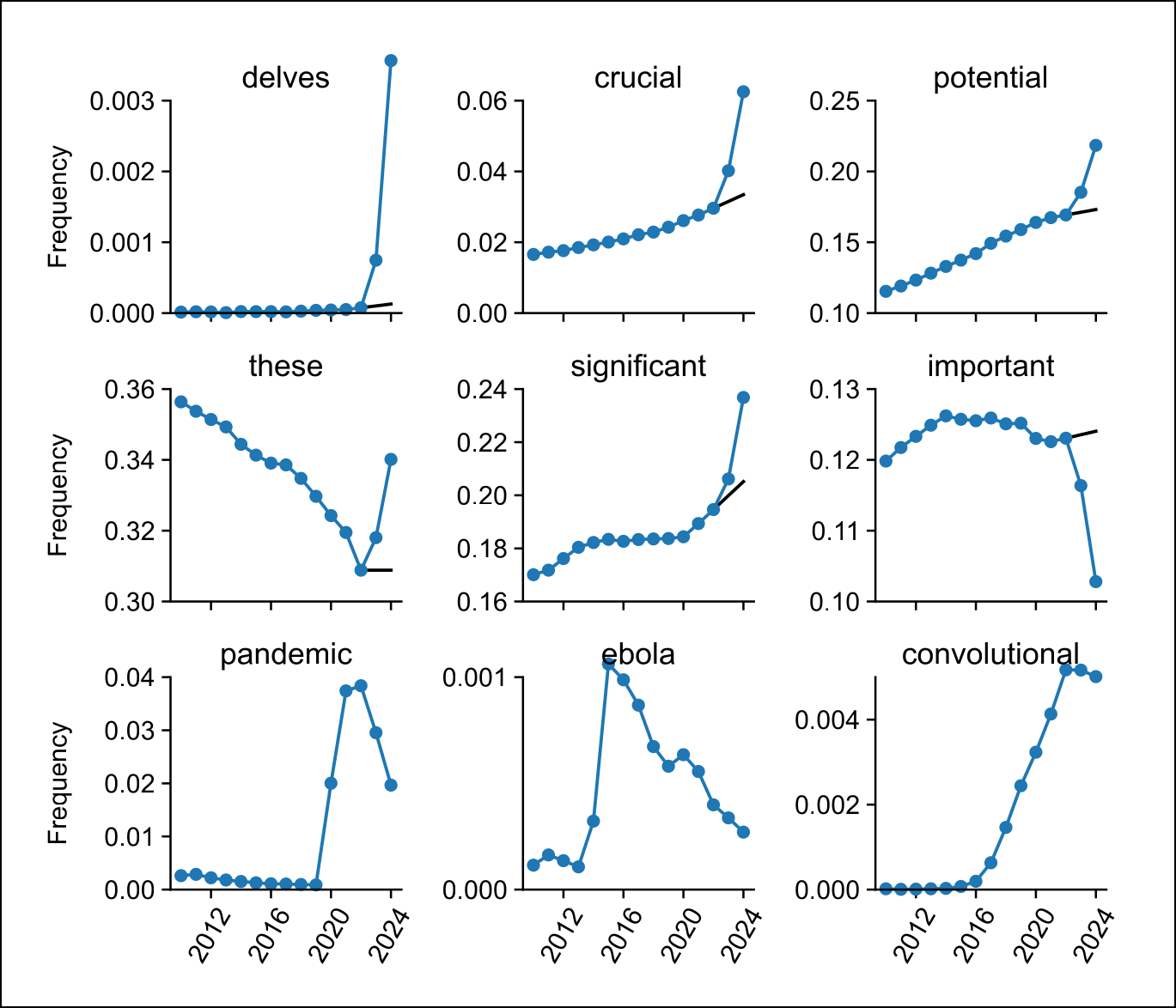 |
| Teksten in PubMed schakelden plots vanaf 2023 over van ‘important’ naar ‘significant’ |
Stijlwoorden
Enkele minder voorkomende woorden die volgens deze berekening in 2023 en 2024 overmatig werden gebruikt, waren de werkwoorden ‘delve’ (25 keer meer), ‘showcase’ (9 keer meer) en ‘underscore’ (ook 9 keer meer). Wat vaker voorkomende woorden die plots nog meer werden gebruikt, waren ‘potential’ (4,1 percentpunt meer), ‘findings’ (2,7 percentpunt meer) en ‘crucial’ (2,6 percentpunt meer).
Op zich is zo’n plotse toename van een woord niet zo uitzonderlijk. In 2015 was het woord ‘ebola’ plots heel populair, in 2017 ‘zika’ en in 2020 tot 2022 de woorden ‘coronavirus’, ‘lockdown’ en ‘pandemic’. Het is nu eenmaal normaal dat de biomedische literatuur op het moment dat een ziekte uitbreekt daarover vooral publiceert. Maar het overmatig woordgebruik in 2023 en 2024 verschilde wel fundamenteel met die eerdere pieken.
Zo ging het bij de eerdere pieken voornamelijk om inhoudelijke woorden, termen met een specifieke betekenis. In 2024 waren daarentegen bijna alle overmatige woorden stijlwoorden, die eerder een gevoel willen opwekken. Een ander verschil is dat overmatige woorden voorheen bijna allemaal zelfstandige naamwoorden waren, terwijl nu twee derde werkwoorden zijn en een zesde bijvoeglijke naamwoorden. Het gaat nu dus echt om een ander soort overmatig woordgebruik.
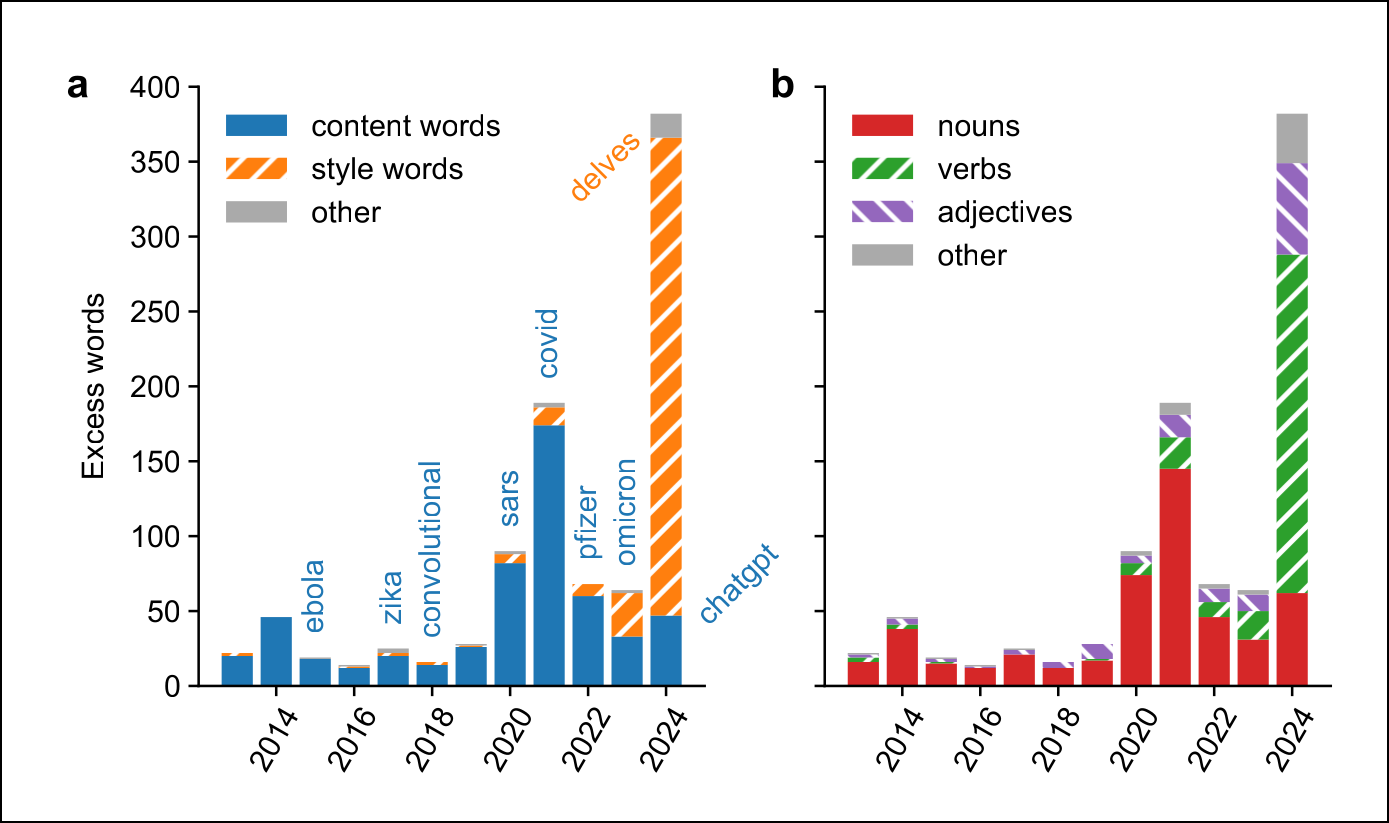 |
| Overmatige woorden in 2024 waren voornamelijk stijlwoorden en werkwoorden |
Dit onderscheid gebruiken de onderzoekers nu om te bepalen hoeveel van die wetenschappelijke artikels (mee) geschreven zijn door ChatGPT. Als het woord ‘potential’ bijvoorbeeld in 2024 4,5 procent meer voorkomt in samenvattingen dan op basis van de trend van de jaren ervoor kon worden verwacht, suggereert dit dat voor minstens 4,5 procent van die samenvattingen ChatGPT is gebruikt om ze te (her)schrijven.
Uiteindelijk vonden de onderzoekers 319 stijlwoorden die overmatig werden gebruikt en leidden ze uit hun cijfers af dat minstens 10 procent van de samenvattingen op PubMed door een taalmodel zijn gegaan. Er bleken ook duidelijke verschillen tussen academische domeinen, landen en publicaties. In computationele domeinen bijvoorbeeld kwamen ze tot een minimumgrens van 20 procent, wellicht omdat die onderzoekers vaak computerwetenschappers zijn, die meer ervaring met AI hebben.
Is dit erg?
Je kunt je afvragen of het erg is dat dit soort woorden nu vaker voorkomt in teksten. Wetenschappers van wie het Engels niet de moedertaal is, kunnen dankzij een taalmodel wel hun grammatica verbeteren en hun tekst leesbaarder maken. Ze kunnen met deze hulp ook vlotter teksten schrijven in het Engels, waardoor ze minder nadeel ondervinden van het feit dat ze geen native speakers zijn. En dat vergroot ook de kans dat hun wetenschappelijke kennis wordt verspreid. Het heeft dus zeker voordelen.
Maar de uitvoer van taalmodellen is ook notoir gemiddeld. Je zult er zelden vernieuwende zaken in lezen. Als alle wetenschappers samenvattingen van hun artikels laten schrijven door ChatGPT, en dit taalmodel bepaalde woorden vaker gebruikt door de manier waarop het is getraind, dan lijken al die samenvattingen sterk op elkaar. Het kan de kwaliteit van wetenschappelijke teksten daardoor verminderen en de verspreiding van wetenschappelijke kennis zelfs tegengaan.
Het gebruik van ChatGPT doet ook sterk afbreuk aan de eigen schrijfstijl. Auteurs hebben zo hun eigen stijl: niet alleen hebben ze een voorkeur voor specifieke woorden, ook specifieke zinsconstructies, uitdrukkingen of zelfs de manier van opbouwen van een tekst. En door die stijl communiceren de schrijvers ook. Trouwe lezers verwachten een bepaalde stijl en voelen zo verbinding met de auteur, alsof ze er een gesprek mee aan het voeren zijn.
Laat je een groot taalmodel een deel van je tekst schrijven of neem je kritiekloos een door ChatGPT herschreven versie van je concepttekst over, dan verlies je een deel van je stijl, en zo ook de verbinding met je lezers. Die krijgen dan het gevoel dat overheerst wanneer je een tekst leest die letterlijk uit ChatGPT komt: zonder ziel, zonder intentie, zonder persoonlijkheid. En als je toch altijd al graag woorden zoals ‘delve’ en ‘crucial’ gebruikte, dan heb je pech. Vanaf nu neemt niemand je teksten nog serieus.
